
MPLS. Эту аббревиатуру слышал, наверное, каждый сетевой инженер. Кто-то побаивается этой темы, кто-то уже на “ты”, например, с такими понятиями как L3VPN, VPLS, xconnect и т.д. Каким бы сложным или пугающим не был MPLS, но на сегодняшний день эта технология является очень распространенной и востребованной, особенно у операторов связи, пусть и не в чистом ее проявлении. И в данной статье мы постараемся подробно разобраться в том, зачем же вообще нужен MPLS сегодня, как он работает и т.д.
Да, на тему MPLS в интернете есть статьи или вебинары (например, “Сети для самых маленьких”, или даже у нас уже был вебинар по данной теме), но время идет, что-то появляется новое, что-то старое забывается, к тому же в данной статье мы рассмотрим все очень подробно, и все это будет в рамках одной этой статьи для удобства (как мы делали это, к примеру, в статье по spanning-tree), ну и, конечно же, рассмотрим модельный ряд и реализацию функционала MPLS на коммутаторах SNR, ведь без теории не бывает и практики. Но если кто-то прекрасно представляет и понимает, что такое MPLS, и как он работает, то может переходить сразу же к последней главе о коммутаторах SNR.
Тема очень объемная и непростая, поэтому без лишних прелюдий предлагаю начать.
Наверняка, многие прекрасно знают, что базовый MPLS на сегодняшний день практически нигде не используется, а используются так называемые MPLS технологии или приложения. Однако без понимания базовых принципов работы MPLS будет невозможно разобрать интересующие нас MPLS приложения и работу MPLS на коммутаторах SNR, поэтому принципы работы базового MPLS необходимо освежить, ну или объяснить, если кто-то впервые с этим сталкивается.
Итак, MPLS (от англ. “MultiProtocol Label Switching” - многопротокольная коммутация по меткам) - это технология, использующая при передаче данных от одного узла к другому метки вместо адресов сетевого уровня. Основная идея MPLS - коммутировать пакеты, не заглядывая в заголовок протокола L3 уровня.
Это возможно благодаря метке, присваиваемой пакету. Метки распространяются от маршрутизатора к маршрутизатору: перед передачей данных в MPLS-сети маршрутизаторы предварительно обмениваются метками, сообщая друг другу, как добраться до той или иной сети и какую метку использовать для этого. Так формируется путь для передачи трафика.
По мере продвижения пакета на нем только меняются метки, поэтому в определении как раз ключевое слово “switching” (коммутация), а не “routing” (маршрутизация). Метка помещается между L2 и L3 заголовками, именно поэтому и не приходится анализировать заголовок L3.
Возникает логичный вопрос, а что такого в том, чтобы осуществлять стандартный лукап: посмотреть dst.ip в заголовке пакета и найти соответствующую запись в таблице маршрутизации, зачем было изобретать какие-то метки?
Чтобы ответить на этот вопрос, вернемся немного назад в прошлое, а также рассмотрим основные принципы L2 и L3 форвардинга.
Layer 2 Forwarding подразумевает поиск точного совпадения в таблице MAC-адресов.
Кадры отправляются как есть: не нужно менять MAC отправителя/получателя, обновлять TTL, пересчитывать FCS (контрольную сумму) и т.д.
Из-за своей относительной простоты Layer 2 Forwarding может быть легче имплементирован в аппаратном использовании: ASICs (Application-Specific Integrated Circuit) и CAM память (Content-Addressable Memory).
Не нужно отправлять пакет в CPU для принятия решений о форвардинге (кроме редких случаев, когда служебный broadcast/multicast/unicast трафик имеет dst.mac самого коммутатора, тогда да, трафик будет направлен в CPU для обработки, но по сравнению с обычным пользовательским трафиком происходит это не так часто).
Layer 3 Forwarding включает в себя поиск более специфичного совпадения в таблице маршрутизации.
Частичное совпадение - это нормально. Все дело в маске подсети. Пакет с определенным dst.ip может попадать под несколько правил в таблице маршрутизации, но выбран будет именно наиболее специфичный маршрут - с самой длинной маской.
Например, приходит пакет с определенным dst.ip, маршрутизатор (или L3-коммутатор) смотрит таблицу маршрутизации на поиск более специфичного маршрута. Когда находит - отправляет пакет в соответствующий интерфейс.
Также маршрутизатору необходимо уменьшить IP TTL, пересчитать IP Header Checksum, изменить src/dst MAC-адреса и пересчитать Ethernet FCS, прежде чем отправлять пакет.
То есть, L3 Forwarding гораздо сложнее, чем L2. Поэтому ранее Layer 3 Forwarding, как правило, выполнялся с помощью средств CPU (софтово).
И это делало маршрутизаторы гораздо медленнее, чем коммутаторы (каждое сообщение занимало больше времени на обработку, поскольку CPU гораздо медленнее, чем те же ASICs).
Однако ASICs и TCAM (Ternary Content-Addressable Memory) память позволяют некоторому Layer 3 Forwarding быть выполненным аппаратно (хардварно).
CAM память - бинарная (т.е. использует только 0 и 1), соответственно может искать только полностью совпадающее значение
TCAM - вид памяти (аппаратной, как и CAM), который не требует точного совпадения, при возвращении результата.
В отличии от CAM используется три значения, а не два (из названия: “ternary” - тройной): 0,1 и X (под “X” имеется в виду - что угодно). Такая память как раз подходит для IP-маршрутизации, ведь при L3 форвардинге ищется не точный маршрут, а наиболее специфичный.
Но ранее, TCAM и ASICs не существовало, да и аппаратная IP-маршрутизация в принципе была очень дорогим удовольствием. Поэтому изначально MPLS и был придуман для этой цели, чтобы обеспечить высокопроизводительную коммутацию IP-пакетов.
Но спустя время все же появилась и TCAM память, и чипы ASICs.
И если ранее существовали только Software-Based маршрутизаторы (которые принимали решения о форвардинге только программно, используя CPU), то позднее появились и Hardware-Based маршрутизаторы (CPU управляет control plane, а ASICs используются для передачи пакетов для управления data plane), и Hybrid маршрутизаторы (CPU также обрабатывает control plane, но data plane управляется другим компонентом - NP (Network Processor)).
Помимо всего прочего появилась новая технология (на ходовом на тот момент вендоре) - Cisco Express Forwarding (CEF).
CEF полагается на два готовых кеша в data plane для ускорения обработки пакета:
Грубо говоря, FIB предоставляет L3 информацию о next-hop, а Adjacency table предоставляет L2 информацию (о next-hop и directly connected устройствах).
CEF выполняется как на software-based маршрутизаторах (Software CEF), так и на Hardware-Based маршрутизаторах (Hardware CEF).
В Software CEF FIB и Adjacency table хранятся в оперативной памяти (RAM) и обрабатываются CPU.
В Hardware CEF FIB хранится в TCAM, а у Adjacency table своя отдельная память. Обрабатываются ASIC или NP (Network Processor).
И хотя Software CEF не достигает по скорости hardware-forwarding передачи, она все равно достигает гораздо большей скорости чем Process switching (технология передачи, которая использовалась до создания CEF).
Но, разумеется, Hardware CEF предоставляет наибольшую производительность.
И зачем же тогда после этого остался нужен MPLS? Почему он используется до сих пор, несмотря на то, что CEF используется на всех современных Cisco-устройствах по умолчанию, или что сейчас практически на любом вендоре, все коммутаторы построены на ASICs?
Дело в том, что философия MPLS - не заглядывать внутрь IP-пакета, и это дает определенные преимущества:
Итак, на сегодняшний день MPLS в чистом виде мало кому интересен. Но приложения, которые строятся поверх MPLS используются повсеместно.
Основные приложения MPLS на сегодняшний день: L3VPN, L2VPN, MPLS TE.
Вернемся к рассмотрению базового MPLS и начнем, разумеется, с терминологии.
Метка (label) - какое-то число от 0 до 2–1. На основе метки MPLS-маршрутизатор принимает решение, что делать с пакетом (изменить, удалить или добавить метку) и куда его передать.
Стек меток (label stack) - каждый пакет в MPLS сети может нести от одной до бесконечного числа меток (до исчерпания лимитов MTU, конечно, если запрещена фрагментация пакетов. Но все же обычно, это всего 2-3 метки). Все метки объединяются в стек. Первая в стеке метка называется верхней (ближе к Ethernet-заголовку), последняя - нижней (ближе к данным). Решение о том, как коммутировать MPLS-пакет, принимается на основе верхней метки.
Заголовок MPLS имеет длину 32 бита:

Рис. 1. Формат заголовка MPLS
- Label (20 бит) - значение метки. Данное значение может быть от 0 до 1 048 575 (2-1), однако первые 16 значений (от 0 до 15) зарезервированы и используются специальным образом, об этом позже;
- TC (Traffic Class) (3 бита) - в настоящее время используется исключительно для реализации MPLS QoS, и несет в себе приоритет пакета (по аналогии с полем DSCP в IP-пакете). Первоначально поле носило название EXP (экспериментальное), а его содержимое не было регламентировано. Предполагалось, что оно может быть использовано для исследований, внедрения нового функционала, но это в прошлом.
- BoS (Bottom of stack) или просто S (1 бит) - стек меток может содержать бесконечное число меток, но не содержит информации о его длине. S бит установлен у нижней в стеке метки, это сигнализирует о том, что за данной меткой больше нет других меток: в бит S записывается «1», если это последняя метка (достигнуто дно стека) и «0», если стек содержит больше одной метки (еще не дно);
- TTL (8 бит) - данное поле имеет ту же функцию, что и поле TTL в IP заголовке, даже обладает той же самой длиной. Единственная задача - не допустить бесконечного блуждания пакета по сети в случае петли. При передаче IP-пакета через сеть MPLS значение IP TTL может быть скопировано в MPLS TTL, а потом обратно. Либо отсчет начнется опять с 255, а при выходе в чистую сеть IP значение IP TTL будет таким же, как до входа.

Рис. 2. Пример заголовка MPLS
LSR (Label Switched Router) - маршрутизатор, поддерживающий MPLS. Он способен распознавать метки и принимать и отправлять пакеты с метками. В MPLS сети может быть три вида LSR:
LER (Label Edge Router) - это маршрутизатор на границе сети MPLS. Ingress LSR и Egress LSR являются граничными, а значит они по совместительству являются и LER.
LSR может выполнять три операции над метками:
Нужно понимать, что роли маршрутизаторов в MPLS (Ingress LSR, Intermediate LSR, Egress LSR) - это все условные роли, которые не привязываются к какому-то конкретному устройству, потому что пакеты в MPLS-облаке для разных сетей назначения могут проходить по разным путям. Такой путь в MPLS называется LSP.
LSP (Label Switched Path - путь переключения меток) - это однонаправленный канал от Ingress LSR до Egress LSR, то есть путь, по которому фактически пройдет пакет через MPLS-сеть. Иными словами, LSP - это последовательность LSR, через которую проходит MPLS пакет, принадлежащий определенному классу или FEC.
Все пакеты, попадающие в MPLS-облако, группируются особым образом.
FEC (Forwarding Equivalence Class) - группа пакетов, которая пересылается по одному пути и одинаково обрабатывается. Все пакеты, принадлежащие к одному FEC, имеют одинаковую метку (при передаче между определенными узлами). Маршрутизатор, который принимает решение о том, какой пакет принадлежит к определенному FEC - Ingress LSR.
Некоторые примеры FEC:
Грубо говоря, FEC - это классы трафика (даже если брать из названия "equivalence class", т.е. эквивалентный маршрут для определенных (тоже эквивалентных) классов трафика/префикса/сети назначения). Важно понимать, что пакеты одного FEC не обязаны следовать на один и тот же адрес назначения. И в то же время, если даже два пакета следуют в одно место, то они необязательно будут принадлежать одному FEC. Сейчас в качестве FEC может выступать только IP-префикс. Такие вещи как маркировка QoS не рассматриваются.
Для каждого FEC выстраивается свой путь через MPLS-облако. Ingress LSR и FEC определяют LSP, задавая точку входа и выхода соответственно (поэтому даже если пакеты предназначаются одному FEC, LSP у них могут быть разные, так как могут быть разные точки входа, если пакеты отправляются с разных Ingress LSR).
Если рассматривать последовательность LSR (LSP) для определенного FEC, то LSR можно разделить на следующие типы:
Отсюда вытекают важные нюансы:
Всю работу по распознаванию FEC и определению по какому LSP пойдет трафик берёт на себя Ingress LSR: получив чистый пакет, он его анализирует, проверяет, какому классу тот принадлежит, и навешивает соответствующую метку. Пакеты разных FEC получат разные метки и будут отправлены в соответствующие интерфейсы. Пакеты одного FEC получают одинаковые метки.
Для того, чтобы построить LSP, все LSR должны соблюсти следующие условия:
LIB (Label Information Base) - таблица меток (аналог таблицы маршрутизации (RIB) в IP), в ней указано для каждой входной метки, что делать с пакетом — поменять метку или снять ее и в какой интерфейс отправить.
Для каждого FEC LSR присваивает локальную метку. Локальную метку LSR распространяет всем своим соседям. Также LSR получает метки, распространяемые его соседями. Метки, полученные от всех соседей, и локальную метку LSR сохраняет в таблицу LIB.
LSR выбирает из всего множества полученных от соседей меток одну.
LFIB (Label Forwarding Instance Base) - это таблица коммутации MPLS-пакетов, к которой обращается сетевой процессор (аналог FIB таблицы). При получении нового пакета нет нужды обращаться к CPU и делать лукап в таблицу меток - всё уже под рукой.
Для каждого FEC LFIB содержит:
- Входящую метку (Input Label) - это локальная метка для FEC на определенном LSR;
- Исходящую метку (Output Label). Выбирается LSR из всех полученных от соседей для определенного FEC на основе лучшего пути в таблице маршрутизации.
Как мы уже говорили, первоначальная идея MPLS заключалась в быстрой коммутации пакетов (то есть, максимально разнести control plane и data plane).
Но с появлением дешевых чипов (ASICs) и FIB таблиц, IP-передача в сетях стала простой и быстрой, и маршрутизатору (L3-коммутатору) без разницы куда смотреть - в FIB или LFIB, а вот то, что действительно важно, так это то, что MPLS все равно, данные каких протоколов передаются под ним.
Тем не менее, разработчики разнесли отдельно control plane и data plane в MPLS. Задача control plane на LSR - наполнить таблицы LIB и LFIB метками для каждого FEC. Задача data plane - коммутировать MPLS пакеты на основе LFIB.
Для начала рассмотрим более подробно процесс распространения информации о метках.
Метки можно распространять как статически (назначить вручную), так и динамически, с помощью специальных протоколов.
Вручную это делать не очень неудобно, поэтому в современном мире, как правило, используются специальные протоколы распространения меток.
Существует три базовых протокола для распространения меток: LDP, RSVP-TE и MP-BGP.
Если коротко, то LDP - самый простой и самый распространенный способ, который опирается на маршрутную информацию узлов.
RSVP-TE - это развитие некогда разработанного, но непопулярного протокола RSVP (Resource Reservation Protocol). Используется в MPLS-TE (Traffic Engineering) для построения LSP, c возможностью резервирования сетевых ресурсов, например, пропускной способности канала. Для его работы требуются протоколы динамической маршрутизации, поддерживающие Traffic Engineering (OSPF, IS-IS).
MP-BGP (или MBGP, или Multiprotocol-Border Gateway Protocol) - это расширение BGP, которое поддерживает различные типы адресов/протоколов (address families). Однако MP-BGP передает метки немного для других целей, поэтому он стоит немного в стороне от LDP и RSVP-TE.
Мы рассмотрим подробно только LDP (и его подвид - tLDP), также рассмотрим MP-BGP (когда будем изучать L3VPN). А вот RSVP-TE в данной статье мы рассматривать не будем (поскольку на данный момент он не поддерживается на коммутаторах SNR), как и сам Traffic Engineering, при желании можно изучить это самостоятельно в сети Интернет.
Но перед этим несколько слов о том, как LSR работают с метками.
Как уже говорили, метки распространяются в направлении от получателя трафика к отправителю, а точнее от Egress LSR к Ingress LSR (поэтому MPLS и строится навстречу трафику).
Сам же механизм распространения меток зависит от конкретного протокола, настроек и реализации на оборудовании.
1. Существует два варианта организации пространства меток:
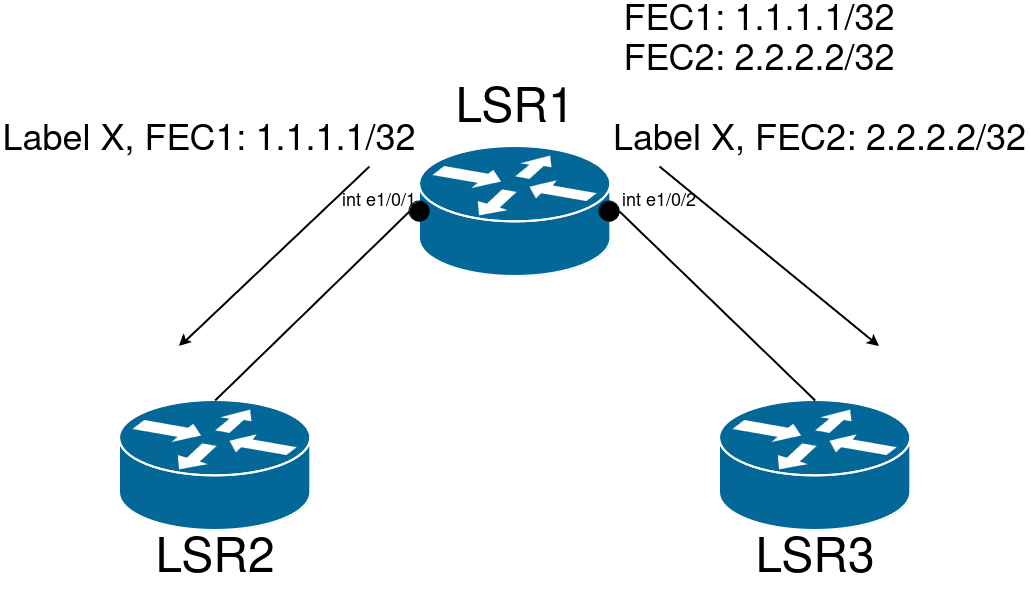
Рис. 3. По-интерфейсное пространство меток
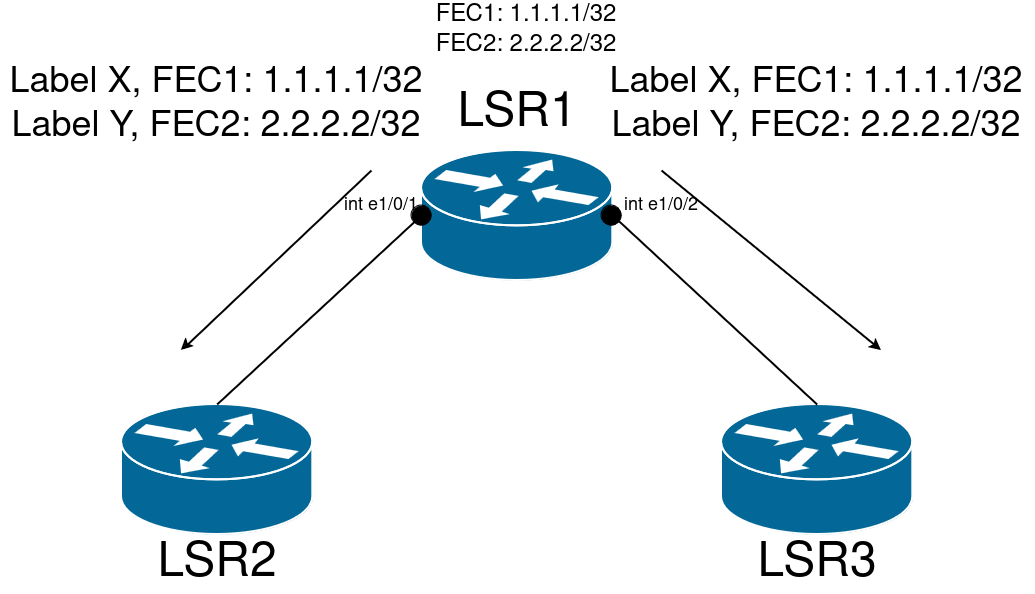
Рис. 4. По-платформенное пространство меток
2. Существует два режима распространения меток:
3. LSR может наполнять LIB двумя способами:
4. Существует два режима хранения меток:
Итого: обычно организовывается какое-то пространство меток (либо по-интерфейсное, где за каждым интерфейсом может существовать одна и та же метка, но для разных FEC, либо по-платформенное, где метка актуальна в пределах LSR), затем эти метки распространяются соседям. Метки всегда распространяются навстречу трафику (от получателя к отправителю). Они могут распространяться как по запросу (Downstream on Demand), так и самостоятельно без запроса (Unsolicited Downstream). При этом таблица локальных меток LIB начинает заполняться сразу же, как только появился FEC (Independent LSP Control), либо только когда пришла метка с данным FEC от downstream LSR (Ordered LSP Control). Хранится может либо только одна метка для экономии пространства меток (Conservative Label Retention), либо сразу несколько меток, если есть несколько путей, что улучшит время сходимости (Liberal Label Retention). Все это зависит от реализации на конкретном оборудовании и от конфигурации.
Прежде чем переходить к протоколам распространения меток, рассмотрим зарезервированные метки. Как мы уже говорили выше, первые 16 значений метки (от 0 до 15) зарезервированы и не могут использоваться для назначения FEC. LSR назначает специальную функцию каждой из них.
Метка 0 - Explicit NULL, метка 1 - Router alert, метка 2 - IPv6 Explicit NULL, метка 3 - Implicit NULL, метка 14 - OAM alert. Остальные зарезервированные метки в данный момент не используются.
0 - IPv4 Explicit NULL (от англ. “явный”). Эта метка используется перед Egress LSR для того, чтобы уведомить его, что данную метку 0 можно снять, не просматривая LFIB-таблицу, а под данной меткой уже будет расположен IPv4-заголовок.
Для тех FEC, что зарождаются локально (для directly connected сетей) Egress LSR выделяет метку 0 и передает своим соседям - предпоследним LSR в LSP (Penultimate LSR). То есть Egress LSR говорит о том, что для того, чтобы добраться до его directly connected сетей, нужно использовать метку 0. Соответственно при передаче пакета предпоследний LSR меняет текущую метку на 0, и когда Egress LSR получает пакет с меткой 0, он знает, что данную метку нужно просто удалить и приступить к обработке IP-пакета.
1 - Router alert (предупреждение маршрутизатора). Эта метка может присутствовать в любом месте стека, кроме нижней метки. Когда метка 1 верхняя в стеке, это означает, что пакет требует дополнительной обработки. Следовательно, пакет не обрабатывается аппаратно (с помощью ASIC), а обрабатывается программно (с помощью CPU). Коммутация пакета осуществляется на основании следующей за router alert метки в стеке. Однако после того как LSR определил исходящую метку и провел требуемую с ней операцию, router alert метка навешивается на верх стека и пакет коммутируется далее. Router alert метка используется по аналогии с одноименной опцией в заголовке IP-пакета.
2 - IPv6 Explicit NULL Label. Тот же самый Explicit NULL (метка 0), только для IPv6-префиксов.
3 - Implicit NULL (от англ. “неявный”). Если Egress LSR требуется, чтобы пакет от upstream LSR для какого-либо FEC поступал уже без метки, он анонсирует этот FEC с меткой 3. Получение от downstream LSR метки Implicit NULL заставляет LSR при коммутации MPLS-пакета удалить верхнюю метку в стеке (то есть, если меток несколько, то будет удалена только верхняя в стеке), и отправить далее IP-пакет.
Обычно Egress LSR анонсирует свои непосредственно подключенные и суммированные префиксы с меткой Implicit Null.
Хотя метка 3 сигнализирует об использовании механизма Implicit NULL, она никогда не появится в стеке меток MPLS, поэтому она и называется Implicit (неявный).
Если промежуточный (предпоследний) LSR отправит пакет до нашего FEC без метки, то на Egress LSR не будет выполняться поиск в LFIB, чтобы удалить верхнюю метку в стеке, и не будет передаваться пакет процессу IP-маршрутизации, потому что это будет уже IP-пакет, что экономит ресурсы маршрутизатора. Egress LSR может "попросить" своего upstream об этом с помощью метки Implicit NULL. Такой прием называется PHP (Penultimate Hop Popping) (Penultimate LSR - предпоследний LSR), и данный прием работает только в IP-сетях.
Возникает закономерный вопрос: зачем тогда нам нужна метка 0 (IPv4 Explicit NULL), если мы можем снимать метку еще раньше, используя Implicit NULL. Ответ заключается в QoS. Насколько мы помним, в заголовке MPLS может использоваться поле “TC” (Traffic Class) для обеспечения качества обслуживания, и оно может нести какую-то информацию о приоритете. И если мы снимем метку раньше времени, то информация о приоритете пропадет. Поэтому, если нам важно, чтобы MPLS пакет сохранил свой приоритет для дальнейшей обработки, то нам нужно использовать Explicit NULL (0). Если QoS по каким-то причинам не используется, или мы указали приоритет пакета в поле DSCP, то можно снять метку раньше, тем самым сэкономим ресурсы маршрутизатора, с помощью Implicit NULL (3).
14 - OAM Alert (предупреждение функций эксплуатации и управления) - MPLS OAM (Operation and Maintenance) описан в RFC 4377.
При распространении меток существует две глобальные цели: распространение транспортных меток и распространение сервисных меток.
Забегая вперед, транспортные метки используются для передачи трафика по сети MPLS. Для них используются LDP и RSVP-TE.
Сервисные метки служат для разделения различных сервисов. Тут используется либо MBGP, либо подвид LDP - tLDP (targeted LDP).
Роли меток мы рассмотрим позднее.
LDP (Label Distribution Protocol) - протокол распространения меток. Протокол LDP в базовом MPLS служит для распространения информации о метках в MPLS сети. LDP описан в RFC 5036.
В LDP существует четыре базовых механизма:
Вся информация в LDP передается в виде сообщений. Существует четыре категории LDP сообщений:
В стандарте LDP определены следующие сообщения:
Таблица 1
Типы сообщений в LDP
| Наименование сообщения | Тип |
|---|---|
| Notification | 0x0001 |
| Hello | 0x0100 |
| Initialization | 0x0200 |
| KeepAlive | 0x0201 |
| Address | 0x0300 |
| Address Withdraw | 0x0301 |
| Label Mapping | 0x0400 |
| Label Request | 0x0401 |
| Label Withdraw | 0x0402 |
| Label Release | 0x0403 |
| Label Abort Request | 0x0404 |
| Vendor-Private | 0x3E00-0x3EFF |
| Experimental | 0x3F00-0x3FFF |
Все сообщения из каждой категории мы рассматривать не будем, удостоим подробного внимания лишь некоторые - самые важные, когда будем рассматривать механизм работы LDP.
Обмен LDP сообщениями происходит посредством посылки LDP PDU (Protocol Data Unit). LDP PDU состоит из заголовка (PDU Header) и одного или нескольких сообщений (Message), которые мы рассмотрели выше. В свою очередь заголовок содержит следующие поля:
Все сообщения (messages) LDP имеют единый формат:
Параметры в LDP сообщениях кодируются с помощью метода TLV (Type Length Value).
Небольшое отступление для тех, кто не знает и хочет узнать, что такое TLV .
TLV (Type Length Value или tag-length-value) - широко распространенный метод записи коротких данных в компьютерных файлах и протоколах.
TLV - двоичный формат, используемый для представления данных в упорядоченном (структурированном) виде.
TLV обычно считаются очень гибким способом маршалинга данных в протоколах.
Маршалинг (от англ. “marshal” - упорядочивать) - процесс преобразования информации (данных), хранящейся в оперативной памяти, в формат, пригодный для хранения или передачи. Применительно к компьютерным сетям маршалинг означает процесс преобразования данных в формат, в котором данные могут быть переданы по сети. Данные преобразуются в поток байт, упаковываются, делятся на части, передаются по сети средствами сетевого протокола. Принятые данные преобразуются обратно в исходный формат.
Состоит TLV из трех полей: тег (tag), длина данных (length) и, собственно, данные (value).
Tag является идентификатором данных, определяя их назначение. Состоит из одного байта, принимающего значения от 1 до 254. Значения 0 и FF запрещены.
Length - длина поля данных в байтах. Состоит из одного или трех байт. Если первый байт не равен FF, то это и есть значение длины и данное поле состоит из одного байта. Если первый байт — FF, то следующие два байта обозначают длину в диапазоне от 0 до 65 535. Если длина L не нулевая, то далее следует L байт данных.
Value - фактические передаваемые данные, которые могут быть любого типа или формата.
TLV, к примеру, используются также в протоколе LLDP (Link Layer Discovery Protocol) (не путать с протоколом LDP, который мы сейчас рассматриваем. Это разные протоколы).
Итак, вернемся к MPLS, а точнее к LDP.
Как мы сказали ранее, существует четыре базовых механизма LDP. Рассмотрим подробнее.
Используется для обнаружения потенциальных LDP пиров. Существует два варианта механизма обнаружения соседей:
Рассмотрим, как работает базовый механизм.
При включении LDP на интерфейсе LSR начинает периодически рассылать через этот интерфейс hello сообщения на multicast адрес 224.0.0.2 (all routers on this subnet - все маршрутизаторы сегмента). Hello сообщения отправляются в виде UDP пакетов на порт 646. Получив hello, LSR формируют hello-соседство для отслеживания друг друга.
TTL таких пакетов равен 1, поскольку LDP-соседство устанавливается между непосредственно подключенными узлами (но это не всегда так: LDP сессия может устанавливаться для определенных целей и с удаленным узлом, тогда это называется tLDP - Targeted LDP, соответственно используется расширенный механизм обнаружения соседей).
Существует два отличия расширенного механизма от базового:
Формирование LDP соседства между двумя LSR инициирует установку LDP сессии. Если LSR получает одновременно hello сообщения и targeted hello сообщения, то устанавливается targeted сессия.
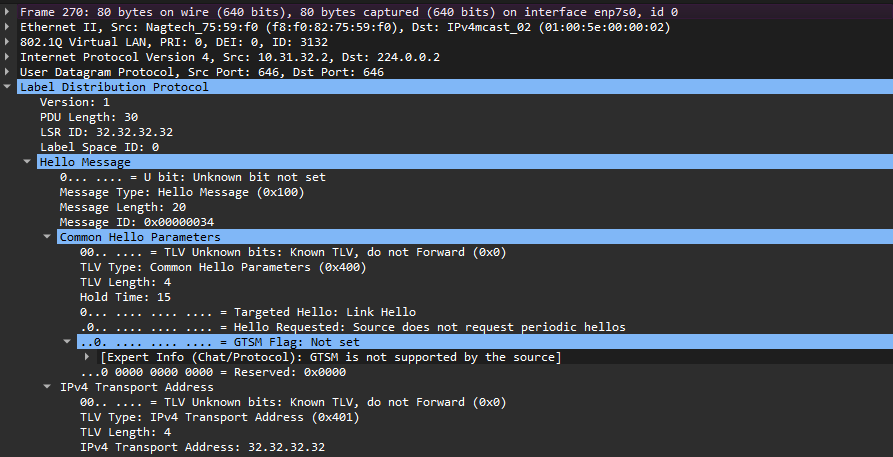
Рис. 5. Пример LDP Hello сообщения
Когда соседи обнаружены, устанавливается соединение с ними - Initialization (теперь TTL всех сообщений, кроме Hello, равен 255).
Для установки и поддержки сессий LSR используют транспортный адрес, TCP порт 646. Важно, чтобы маршрут до транспортного адреса соседа был в таблице маршрутизации LSR, иначе LDP сессия не установится.
Процесс установки LDP сессии можно разделить на два этапа:
Перед установкой LDP сессии LSR определяют роли. Для этого LSR сравнивают транспортные адреса друг друга. Если в Hello сообщении LSR передает Transport Address в поле “IPv4 Transport Address TLV”, то будут сравниваться именно эти адреса из TLV. Если LSR не отправляет Transport Address в TLV, то для сравнения будет использоваться адрес, с которого отправляется Hello сообщение. Активный сосед тот, чей транспортный адрес больше, второй, соответственно, пассивный.
Далее происходит установка транспортного TCP соединения (стандартный three-way handshake: SYN, SYN-ACK, ACK). Активный сосед устанавливает TCP соединение на порт 646 пассивного соседа. В рамках этого TCP соединения начинается инициализация LDP-сессии.
Еще раз акцентируем внимание, что поиск соседей, а если быть точнее, Discovery сообщения используют UDP в качестве транспорта (порт 646), и TTL данных сообщений равен 1, а вот Session, Advertisement и Notification сообщения используют уже TCP (порт также 646), и TTL в данном случае уже равен 255.
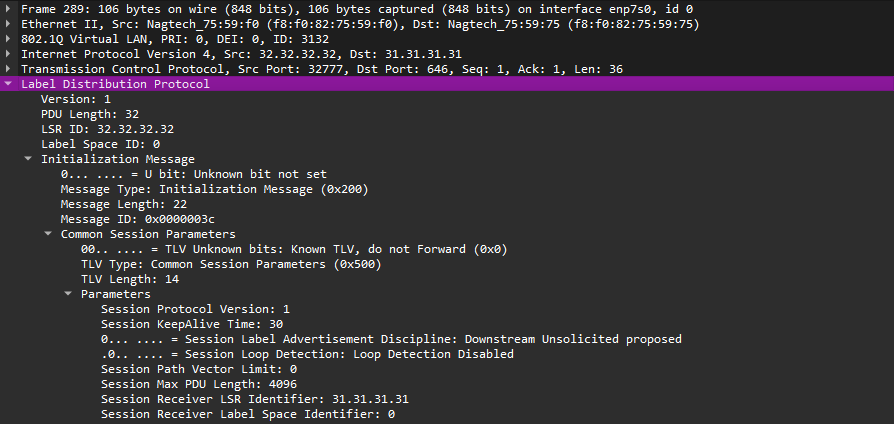
Рис. 6. Пример LDP Initialization сообщения
Рассмотрим более подробно процесс инициализации:
После отсылки keepalive сообщения активный сосед считает сессию установленной. После получения keepalive сообщения пассивный сосед считает сессию установленной.
После этого LSR будут и дальше периодически обмениваться Keepalive сообщениями (по TCP) и будут искать потенциальных соседей с помощью Hello сообщений.
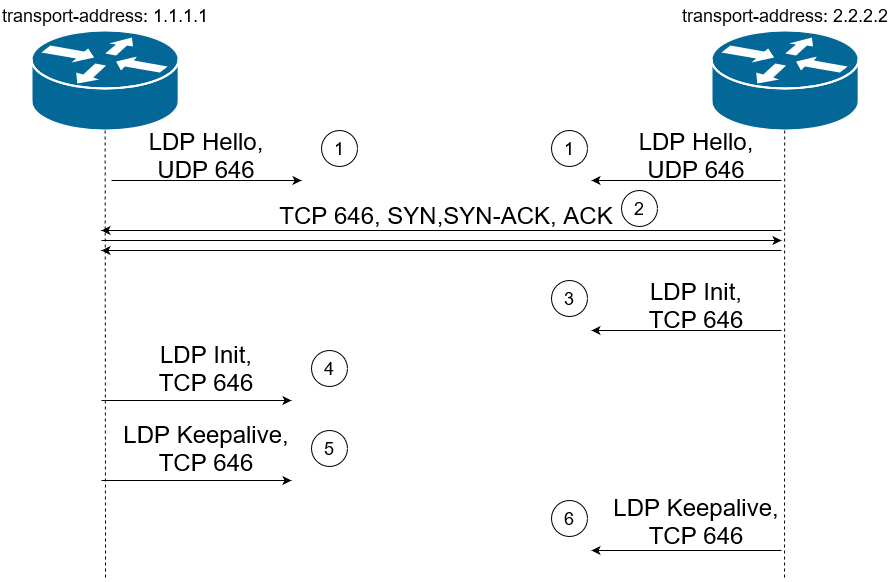
Рис. 7. Процесс инициализации LDP-сессии (нумерация на рисунке НЕ соответствует нумерации в пунктах выше)
Такой порядок инициализации обусловлен тем, что процесс установки сессии реализован в виде конечного автомата. А получение initialization или keepalive сообщения, в момент инициализации, является триггером к смене состояний.
Если в процессе инициализации LSR получает любое LDP сообщение, кроме initialization или keepalive, то LSR немедленно отправляет соседу сообщение уведомления (NAK) и закрывает транспортное TCP соединение.
Если в процессе инициализации параметры LDP-сессии не совместимы, то LSR, выявивший несовместимость параметров, отправляет соседу сообщение уведомления (NAK) и закрывает транспортное TCP соединение.
LDP использует регулярное получение LDP PDU как индикатор целостности LDP-сессии. Для этого LSR поддерживает специальный Keepalive таймер для каждого пира. Таймер сбрасывается каждый раз при получении LDP PDU от пира. Если keepalive таймер истечет раньше, чем LSR получит LDP PDU, то LSR считает, что есть какие-то проблемы в сети на пути передачи пакета или проблемы с пиром и разрывает сессию.
LSR может в любой момент завершить LDP-сессию, перед этим он должен уведомить пира с помощью отправки Shutdown сообщения (Notification message с определенным TLV / Status Code).
Сообщения “уведомление пиров” сигнализируют LDP-соседу о событиях, требующих какой-либо реакции. Такие события могут быть как фатальными ошибками, так и просто информационными сообщениями. В случае получения сообщения о фатальной ошибке пиры должны немедленно разорвать LDP-сессию.
Информация о метках в LDP распространяется с помощью сообщений Label Mapping. В одном Label Mapping сообщении передается два обязательных параметра:
FEC-элементы могут быть двух типов (на самом деле, их гораздо больше):
Label TLV обычно бывают Generic Label TLV. Этот тип используется для Ethernet линков. Имеет одно значение: Label - номер метки, присвоенной FEC.
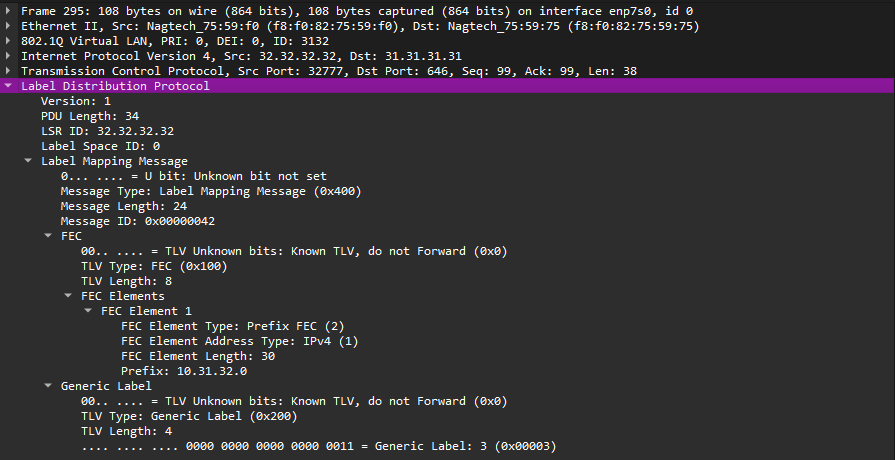
Рис. 8. Пример LDP Label Mapping сообщения
При получении Label Mapping сообщения LSR не будет инициировать создание нового такого сообщения, чтобы отправить данную информацию куда-то дальше. Полученное соответствие будет просто записано в LIB-таблицу, поэтому LDP сообщения не будут блуждать по сети, пока у них не истечет TTL (о TTL немного подробнее поговорим еще ниже).
Но все-таки, как конкретно метка для определенного FEC попадает в LFIB маршрутизатора?
Когда маршрутизатор (или L3-коммутатор) получает информацию о метках, он сохраняет ее в LIB. В LIB обычно лежит локальная метка (local binding) - метка, которую маршрутизатор сам присваивает для определенного FEC, и удаленные метки (remote binding) - метки, полученная от соседей для данного FEC. Помимо меток в LIB заносится идентификатор LSR, от которого получены данные метки (для remote binding).
И даже если у нас есть несколько удаленных меток, полученных от соседей, в LFIB попадет только одна, ведь Downstream LSR выбирается на основе лучшего маршрута из таблицы маршрутизации (кроме случаев, когда в таблицу маршрутизации попадает более одного маршрута с одинаковой метрикой, тогда будет осуществляться баланисировка трафика - ECMP over LDP). И если мы посмотрим в таблицу маршрутизации, то действительно увидим, какой next-hop и интерфейс используется для достижения определенной сети (определенного FEC). Но откуда именно LSR узнает, что трафик для данного next-hop нужно пометить определенной меткой? И откуда он узнает, что данный next-hop сконфигурирован на другом LSR? Ведь в таблице LIB у нас есть только соответствие метки и идентификатора LSR.
Значит LSR нужно как-то сообщить соседу список IP-адресов, сконфигурированных на своих интерфейсах. Для этого используются LDP сообщения Address. Address сообщения имеют обязательный параметр “Address List TLV”, который и содержит список адресов, сконфигурированных на LSR. Получив Address сообщение, LSR добавляет соответствие LSR-ID и адресов в этом сообщении в свою внутреннюю базу. И тогда у нас будет все необходимое для коммутации MPLS-пакета: мы знаем, что сеть назначения находится за определенным next-hop, узнаем, что наш next-hop лежит на маршрутизаторе с определенным идентификатором, а метка, полученная от данного маршрутизатора, нам тоже известна. После этого LFIB будет заполнен, LSP построен, и трафик будет коммутироваться на основе MPLS-меток.
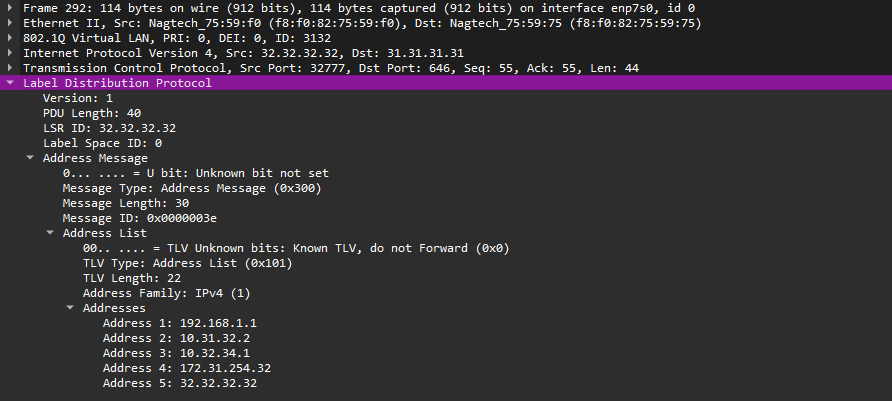
Рис. 9. Пример LDP Address сообщения
Небольшой итог по LDP:
Но вообще, реализация LDP, зачастую зависит от вендора, везде могут быть свои нюансы: например, на одном вендоре по умолчанию может использоваться режим распространения меток Downstream On Demand, а на другом - Unsolicited Downstream, или на одном вендоре используется режим хранения меток Liberal Label Retention Mode по умолчанию, а на другом соответственно Conservative Label Retention Mode, также на разных вендорах в качестве FEC могут использоваться разные адреса: где-то все, включая адреса Loopback-интерфейсов, где-то только /32 адреса и т.д. Да и в принципе, везде могут быть свои нюансы в реализации, но базовый MPLS и LDP обычно работают именно так, как мы рассмотрели, согласно RFC.
В MPLS-пакете поле TTL имеет тот же смысл, что и в IP-пакете. TTL предотвращает от петель, на каждом транзитном узле значение TTL уменьшается на 1, и как только значение TTL достигает 0, пакет должен быть уничтожен.
Когда IP-пакет попадает в MPLS-облако, Ingress LSR уменьшает значение IP TTL на 1 и копирует его в MPLS TTL поле. На Egress LSR значение MPLS TTL из верхней в стеке метки уменьшается на 1 и копируется в поле IP TTL.
Если операция, производимая со стеком меток - “swap”, значение TTL верхней метки, уменьшенное на 1, копируется в заменяемую метку.
Если операция - “push”, значение TTL верхней метки, уменьшенное на 1, копируется во все навешиваемые метки.
Если операция - “pop”, значение TTL верхней метки, уменьшенное на 1, копируется в метку, находящуюся ниже в стеке. Копирование не происходит, если значение TTL верхней в стеке метки больше, чем у метки, находящейся ниже в стеке, это логика механизма защиты от петель.
Intermediate LSR никогда не меняет значение TTL нижележащих меток или значение TTL в IP-пакете.
Итак, мы рассмотрели принцип работы базового MPLS. Но как мы уже говорили, на сегодняшний день базовый MPLS не используется, а вот его приложения применяются очень часто, и начнем мы с L3VPN.
Наверное, стоит начать с того, что такое VPN.
VPN (Virtual Private Network / Виртуальная частная сеть) - это совокупность технологий, позволяющих создавать частные логические сети поверх общей инфраструктуры.
VPN - достаточно объемная тема для изучения, и если мы будем разбирать все типы, протоколы и работу данной технологии, то это по объему получится еще одна большая статья, поэтому предполагается, что читатель уже знаком с данным понятием, или самостоятельно ознакомится с данной темой и изучит ее.
Со своей стороны скажем, что существует два типа VPN:
Пользовательский VPN - это когда пользователь должен позаботиться сам об организации связи (туннеля) между своими точками. В данном случае кадры с частными (серыми) адресами упаковываются в пакеты с публичными адресами и, как в туннеле, летят через публичную сеть Интернет.
В случае же с провайдерским VPN, клиенту не нужно думать об организации сети, провайдер сам предоставит клиенту необходимые каналы.
Далее речь пойдет как раз о провайдерском VPN.
Существуют две модели предоставления VPN сервисов клиентам (с точки зрения способов организации сети):
- Overlay VPN (наложенный VPN). В этой модели оператор связи предоставляет физические или виртуальные каналы точка-точка между маршрутизаторами клиента. Такие каналы могут быть L1, L2 и даже L3. Пример L1 каналов: ISDN, TDM, E1, SDH. Пример L2: ATM, X.25, Frame Relay. Пример L3: использование туннелирования IP, например, GRE, или IPsec. Оператор связи предоставляет клиенту канал (с помощью point-to-point линков или виртуальных каналов (VC)) между каждым маршрутизатором клиента. С точки зрения оператора, маршрутизатор клиента подключается к оборудованию оператора связи. С точки зрения клиента, маршрутизаторы имеют непосредственную связность на L2. Маршрутизация внутри сети клиента прозрачна для сети провайдера, а протоколы маршрутизации выполняются непосредственно между маршрутизаторами клиента. Провайдер не знает маршрутов клиентов и просто отвечает за обеспечение point-to-point передачи данных между точками клиентов.
Модель overlay VPN имеет два ограничения. Одним из них является высокий уровень сложности определения пропускной способности каналов между точками клиента. Второе - это требование развертывания full-mesh point-to-point каналов или VC на магистральной сети оператора связи для достижения оптимальной маршрутизации.
- Peer-to-peer VPN (точка-точка). Модель peer-to-peer использует простую схему маршрутизации для клиента. Сеть провайдера и клиента используют один и тот же протокол маршрутизации, и все маршруты клиента передаются через ядро сети провайдера. В данной модели маршрутизаторы оператора связи коммутируют IP-трафик клиента, кроме того, они участвуют в процессе распространения маршрутов. Таким образом маршрутизаторы оператора связи имеют прямую L3 связность с маршрутизаторами клиента и обмениваются маршрутами.
Но поскольку провайдер теперь участвует в маршрутизации клиентов, в сети клиента необходимо развернуть назначаемое провайдером или общедоступное адресное пространство, поэтому приватная (частная) адресация здесь не подойдет.
Хотя выгода модели peer-to-peer по сравнению с overlay очевидна: Full-mesh развертывание point-to-point линков или виртуальных каналов на магистральной сети оператора связи больше не требуется, а добавление новых точек клиента становится проще, и нет проблем с расчетом пропускной способности каналов. Достаточно просто настроить стык с клиентом. До появления MPLS модель peer-to-peer не была особо популярной, так как при внедрении возникали две большие проблемы:
Для решения этих проблем хорошо подходит MPLS VPN.
MPLS VPN - это модель VPN, сочетающая в себе лучшее из обеих концепций. Он объединяет функции безопасности и разделения клиентов, реализованные в overlay модели, с упрощенной маршрутизацией клиентов, реализованной в традиционной peer-to-peer модели.
И первая проблема (с разделением адресации и пересечением услуг из peer-to-peer модели) решается с помощью концепции VRF.
VRF (Virtual Routing & Forwarding) - это технология, позволяющая иметь одновременно несколько независимых таблиц маршрутизации на одном маршрутизаторе (или L3-коммутаторе). Технология используется для разделения одного маршрутизатора на несколько виртуальных маршрутизаторов.
Каждый такой виртуальный маршрутизатор - это, по сути, отдельный VPN. Их таблицы маршрутизации, список интерфейсов и прочие параметры не пересекаются - они строго индивидуальны и изолированы. Ровно так же они обособлены и от самого физического маршрутизатора (от его глобальной таблицы маршрутизации).
Интерфейсы (только L3-интерфейсы) и маршруты настраиваются, чтобы быть в специальном VRF (так называемом VRF Instance).
VRF не применяется на L2-портах коммутатора. VRF может применяться только на интерфейсах маршрутизатора, SVI, или на L3-портах multilayer коммутатора.
Трафик в одном VRF не может быть отправлен в интерфейс, принадлежащий другому VRF (в качестве исключения может быть настроена технология VRF Leaking, чтобы позволять трафику проходить между VRF).
VRF строго локален для устройства - за его пределами VRF не существует. Соответственно VRF на одном устройстве никак не связан с VRF на другом.
VRF в основном используются для продвижения MPLS.
Однако важно уточнить, что VRF не совсем технология MPLS. Он вполне может существовать и отдельно, это называется “VRF Lite”. Но это не масштабируемое решение, подходит для 2-3 VRF, кроме того, экземпляр VRF необходимо создавать на каждом устройстве на сети.
VRF-lite - VRF без MPLS, или создание провайдерского VPN без MPLS.
VRF-lite обычно используется провайдерами для передачи трафика одним устройством от разных клиентов:
Если мы захотим на разных интерфейсах одного устройства назначить разную адресацию, но при этом из одной подсети, без использования VRF у нас не получится это сделать, и тем более если адресация будет полностью идентичная. Появится примерно следующее сообщение об ошибке: "<IP> overlaps with interface <IFNAME>". Но с использованием VRF мы сможем назначить даже полностью идентичную адресацию на интерфейсах, которые находятся в разных VRF.
Один интерфейс не может быть членом двух VRF сразу или членом и VRF и глобальной таблицы маршрутизации.
Используя VRF Lite можно легко пробросить VPN между разными концами сети. Для этого нужно настроить одинаковые VRF на всех промежуточных узлах и правильно привязать их к интерфейсам
Если какой-то интерфейс не будет состоять в VRF, то он будет в глобальной таблице маршрутизации, и будет изолирован от интерфейсов, которые находятся в каком-либо VRF.
Но данный способ с использованием VRF-lite удобен, пока у нас есть небольшое кол-во клиентов и маршрутизаторов. Но что если у нас будет гораздо больше точек подключения? Что если появится новый VPN? Новый VPN означает новый VRF на каждом узле, новые интерфейсы, новый пул линковых IP-адресов, новый процесс IGP/BGP. Поэтому данный способ является очень плохо масштабируемым.
Опять же, возвращаясь ко второй проблеме выше (в peer-to-peer VPN с большим кол-вом маршрутов): проблема решается тоже довольно просто. Что если о маршрутах клиентов знали бы только те маршрутизаторы, которые непосредственно подключены к клиентским? Но как в таком случае промежуточные маршрутизаторы смогут перенаправлять пакеты? Допустим, пограничный с клиентом маршрутизатор направляет IP-пакет от клиента в сторону сети назначения, и этот пакет, попадая на промежуточный узел, будет уничтожен, ведь промежуточный узел не имеет сети назначения клиента в своей таблице маршрутизации. Первое, что приходит на ум, пакет должен коммутироваться не на основе данных IP-заголовка, а на основе чего-то другого. И тут MPLS с его принципом: "не заглядывать внутрь пакета", приходится очень кстати. Мы берем FEC (префиксы, принадлежащие к одной VPN), присваиваем ему метку, строим LSP и VPN-пакет коммутируется на основе метки MPLS.
Поэтому самое время рассмотреть детально принцип работы MPLS VPN.
MPLS VPN позволяет избавиться от следующих шагов:
Процесс передачи трафика в MPLS VPN можно рассматривать в двух плоскостях:
Начнем с разбора процесса передачи пользовательских данных.
Но для начала введем новые важные термины, которыми будем пользоваться в дальнейшем.
- CE router (Customer Edge router) - пограничное устройство клиента, которое подключается в сеть провайдера. Это маршрутизатор клиента, который непосредственно связан с маршрутизатором оператора. CE - это IP-маршрутизатор, подключается он к PE-маршрутизатору. CE маршрутизаторы не используют MPLS (на них не должен быть запущен MPLS или даже быть его поддержка), его используют только PE- и P-маршрутизаторы);
- PE router (Provider Edge router) - пограничный маршрутизатор провайдера. В плоскости LSP PE является либо Ingress, либо Egress LSR. Собственно, к нему и подключаются CE. Между PE и СЕ есть прямой L3-стык и запущен протокол маршрутизации или маршрутизация сконфигурирована статически. Именно на PE расположены интерфейсы, привязанные к VPN, и именно PE навешивает и снимает сервисные метки.
PE должны знать таблицы маршрутизации каждого VPN, ведь это они принимают решение о том, куда посылать пакет, как в пределах провайдерской сети, так и в плане клиентских интерфейсов.
Поскольку маршруты одного VPN не должны пересекаться с другим, на PE для каждого VPN создается отдельный VRF. VRF включает в себя таблицу маршрутизации (RIB) и CEF-таблицу (FIB), т.е. для каждого VPN на PE есть своя RIB и FIB. Интерфейс PE в сторону CE может принадлежать только к одному VRF, пакеты, полученные через этот интерфейс, будут скоммутированы согласно VRF-таблицам;
- P router (Provider Core router) - транзитный маршрутизатор провайдера в MPLS-домене, который не является точкой подключения CE, а просто осуществляет передачу MPLS-пакетов: пакеты VPN проходят через него без каких-либо дополнительных обработок, иными словами просто коммутируются по транспортной метке. С точки зрения LSP является Intermediate LSR. P-маршрутизатору нет необходимости знать таблицы маршрутизации VPN или сервисные метки.
На P-маршрутизаторе нет интерфейсов, привязанных к VPN, он не содержит маршрутов VPN и VRF-таблиц. P-маршрутизатор не коммутирует пакеты VPN на основе таблицы маршрутизации, он просто прозрачно пропускает через себя MPLS пакеты на основе транспортной метки.
На самом деле, роль P-PE индивидуальна для VPN.
Если в одном VPN R1 и R3 - это PE, а R2 - P, то в другом они могут поменять свои роли.
И вообще, понятия P и PE - это не только понятия L3VPN или L2VPN, данные понятия являются общими терминами, которые обычно используются для обозначения маршрутизатора в сети оператора или на границе MPLS-домена сети провайдера соответственно.
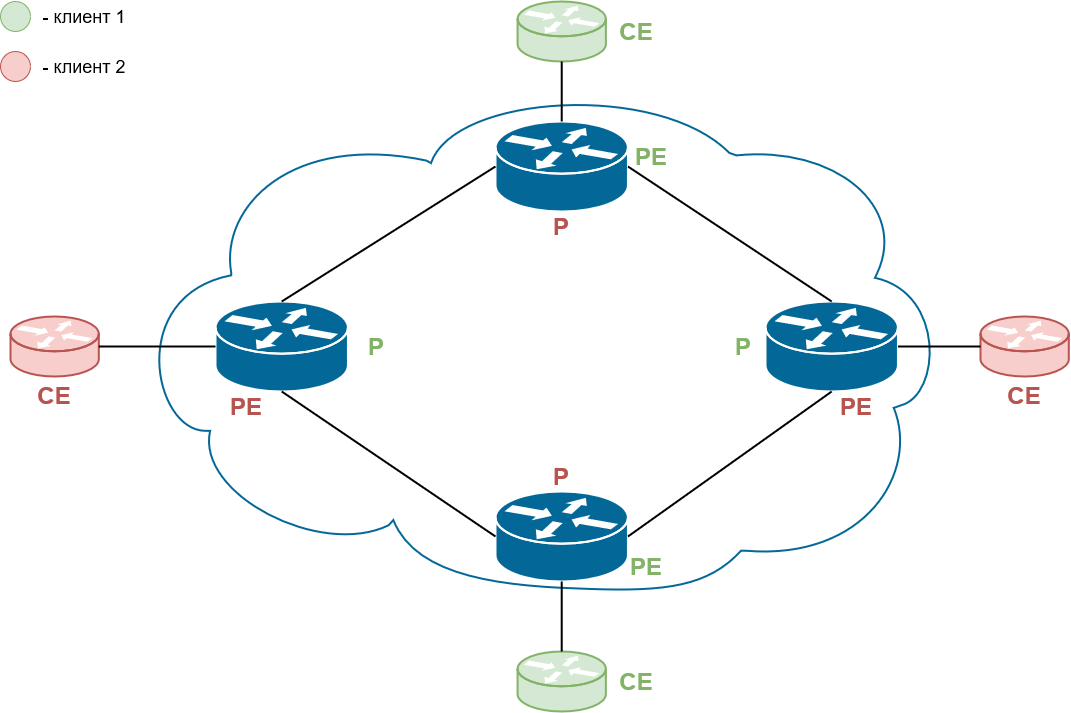
Рис. 10. Пример распределения ролей CE-PE-P в MPLS сети
В MPLS VPN VRF создается только на тех маршрутизаторах, куда подключены клиентские сети. Любым промежуточным узлам не нужно ничего знать о VPN.
Вот какой подход предлагает MPLS VPN: коммутация в пределах магистральной сети осуществляется по одной метке MPLS, а принадлежность конкретному VPN определяется другой, дополнительной меткой - сервисной.
Как это происходит:
1) Клиент отправляет пакет из одной сети в другую сеть. Пока он движется по сети клиента и затем от CE до PE, он представляет из себя обычный IP-пакет, с постоянными Source IP и Destination IP.
2) Когда PE1-маршрутизатор провайдера получает этот пакет на своем интерфейсе, который принадлежит определенному VRF, он проверяет таблицу маршрутизации для этого VRF.
В VRF-таблице маршрутизации PE1 видит, что данный пакет нужно направить в сторону PE2 (на Egress). Если PE1 отправит чистый IP-пакет, то P1 уничтожит этот пакет, так как он не знает маршрут до сети назначения клиента.
Поэтому PE1 отправляет MPLS-пакет с двумя метками в стеке (операция PUSH):
Как именно распространяются транспортные и сервисные метки, мы еще не раз проговорим.
3) P1 анализирует верхнюю (транспортную) в стеке метку, согласно LFIB-таблице меняет метку (операция SWAP) и отправляет MPLS-пакет в сторону P2 (сервисная же метка никогда не меняется на протяжении всего LSP).
4) P2 снова меняет верхнюю метку в стеке и отправляет MPLS-пакет в сторону PE2.
Либо может использоваться механизм PHP (Penultimate hop popping) и тогда P2 снимет транспортную метку, и на PE2 придет пакет только с сервисной меткой.
5) PE2, получив MPLS-пакет снимает верхнюю метку (операция POP, если мы не использовали PHP в предыдущем шаге), затем он анализирует сервисную метку и понимает, что этот пакет нужно коммутировать с помощью VRF-таблицы VPN. И отправляет IP-пакет в сторону CE, сняв перед этим и сервисную метку на выходе с интерфейса.
Роль меток MPLS
Транспортная метка.
Транспортная метка - верхняя в стеке (т.е. находится между L2-заголовком и сервисной меткой. Она является верхней в стеке, потому что на ее основе принимается решение - куда отправлять пакет).
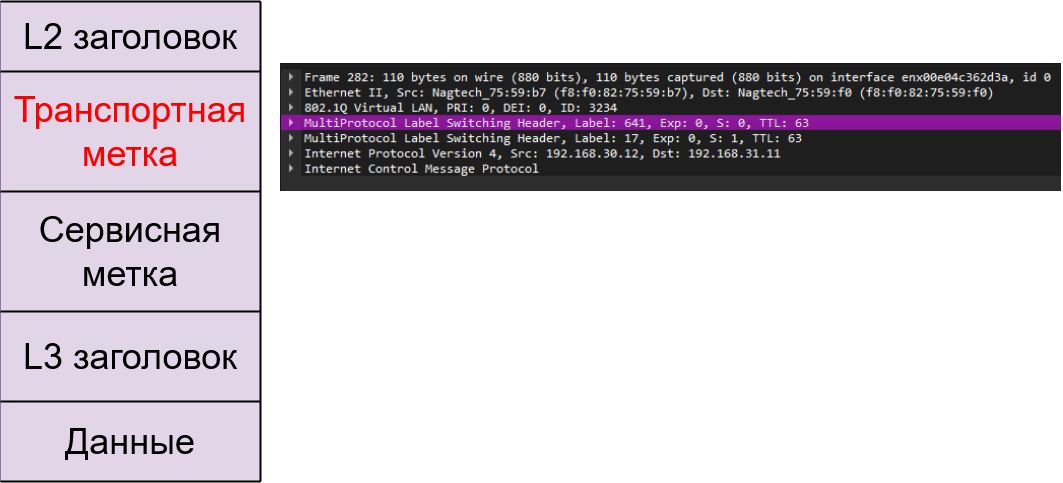
Рис. 11. Транспортная метка
Распространением транспортных меток занимаются протоколы LDP и RSVP-TE.
В целом, здесь всё и так уже понятно, как именно происходит продвижение MPLS-пакета, изменение, снятие меток и прочее, все мы это уже неоднократно рассматривали.
Обратим внимание только на одну деталь - FEC.
FEC здесь уже не сеть назначения пакета (частный адрес клиента), это адрес Egress LSR в сети MPLS, куда подключен клиент.
Дело в том, что LSP не в курсе про VPN, соответственно, он ничего не знает о их приватных маршрутах/префиксах. Зато он знает адреса интерфейсов Loopback всех LSR. К какому именно LSR подключен префикс клиента, подскажет BGP (об этом расскажем далее в главе Control plane) - это и будет FEC для транспортной метки.
Сервисная метка.
Сервисная метка - нижняя в стеке (т.е. находится между транспортной меткой и IP-заголовком). Она является уникальным идентификатором префикса в конкретном VPN. То есть это не идентификатор самого VPN, а именно идентификатор префикса, и он может быть разным для разных FEC одного VPN. Она добавляется Ingress LSR и больше не меняется нигде до самого Egress LSR, который в итоге её снимает.
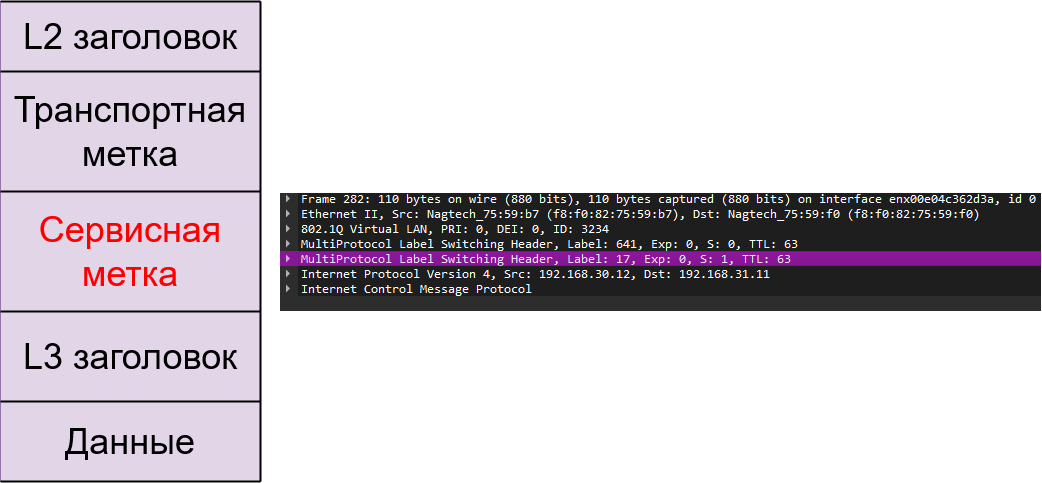
Рис. 12. Сервисная метка
FEC для сервисной метки - это префикс в VPN или, грубо говоря, подсеть назначения изначального пакета.
То есть Ingress LSR должен знать, какая метка выделена для этого VPN.
Для двух разных VPN отличаются сервисные метки: по ним выходной маршрутизатор узнает, в какой VRF передавать пакет.
А транспортные могут быть одинаковые для пакетов обоих VRF, если они используют один LSP.
Передачу пользовательских данных от одного узла клиента до другого мы уже рассмотрели, теперь рассмотрим, как происходит передача служебной (маршрутной) информации.
Чтобы передать информацию о транспортных метках, используется протокол LDP или RSVP-TE. Чтобы передать маршрутную информацию и информацию о сервисных метках, должен использоваться какой-то другой протокол. Как мы сказали ранее, сервисная метка - это идентификатор префикса конкретного VPN, и он может быть разным для разных FEC одного VPN. Поэтому вопрос с распространением меток связан напрямую с распространением маршрутной информации. Т.е. нам нужен протокол, который доставляет от PE к PE маршрут, его метку, и, возможно, еще какой-то набор атрибутов. IGP протоколы в данном случае явно не подойдут, поскольку нам необходимо передавать маршруты от PE к PE, а сеть может быть очень большая и с большим кол-вом маршрутов, а еще эти маршруты нужно как-то отделять друг от друга. Поэтому используется BGP (Border Gateway Protocol). Поскольку сессия должна быть установлена между двумя маршрутизаторами одной AS, которые подключены не напрямую, то должен использоваться iBGP. Но если быть точнее, используется MBGP.
MBGP (MP-BGP, Multiprotocol-Border Gateway Protocol) - это расширение BGP, которое поддерживает различные типы адресов/протоколов (Address familiy).
Если ранее BGPv4 мог передавать только IPv4 unicast маршруты, то MBGP легко масштабируется и с помощью так называемых Address family он может передавать маршруты не только IPv4 unicast, но и IPv6, multicast, VPNv4, VPNv6, L2VPN и т.д.
MBGP так же как и обычный BGP работает на control plane “уровне”, а именно позволяет договориться маршрутизаторам о том, как использовать тот или иной префикс и нужно ли его добавлять в таблицу маршрутизации. За data plane и передачу информации отвечает MPLS.
Address family - сущность, которая используется для того, чтобы BGP мог передавать не только IPv4 unicast, но и информацию других протоколов. Address family используется, чтобы мы могли управлять и отслеживать трафик одного типа/протокола (IPv4, IPv6 и т.д.) для разных VRF.
В секции NLRI (Network Layer Reachability Information, или Информация сетевого уровня о доступности сети - IP-префикс и длина префикса) в обычном сообщении BGP Update переносится сам префикс.
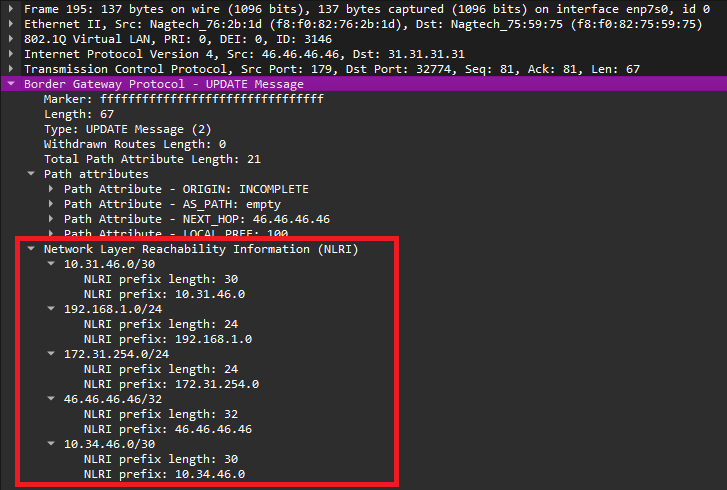
Рис. 13. Пример сообщения Update из обычного BGP
MBGP в отличие от BGP имеет атрибут MP_REACH_NLRI, в котором используются определенные address family, описывающие протокол сетевого уровня, адреса которого передаются в секции NLRI.
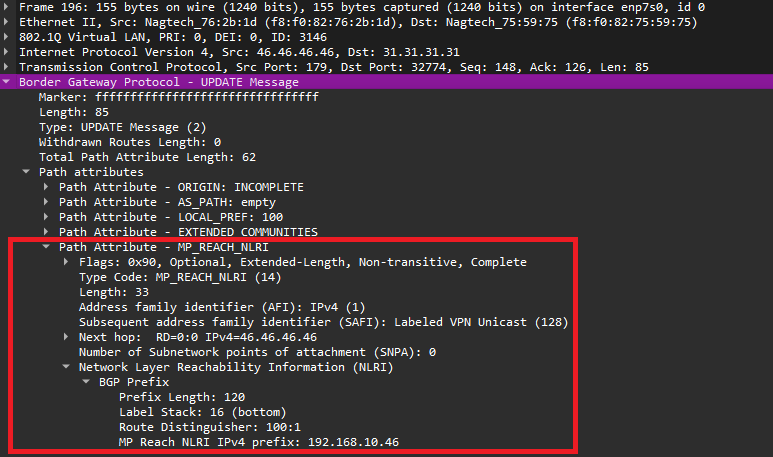
Рис. 14. Пример сообщения Update из MBGP
Нас сейчас более всего интересует address family - VPNv4.
Основные атрибуты VPNv4: маршрут, метка, Route Distinguisher, Route Target.
Каждый маршрут в MBGP уникален. А если быть точнее, есть такое понятие как VPNv4-маршрут. Именно им оперирует MBGP.
Такой маршрут состоит из обычного IPv4-префикса и специальной приставки перед ним - RD (Route Distinguisher).
VPNv4 = RD + IPv4
У каждого VRF свой RD, и все маршруты этого VRF будут передаваться MBGP с одинаковым RD, а все маршруты другого VRF с другим RD. Так VPNv4-маршруты не смешиваются (от англ. “Distinguish” - различать).
RD (Route Distinguisher) - 64-битное поле, используется для того, чтобы сделать VPN-префиксы уникальными при распространении через MBGP. RD состоит из двух полей:
Тип 0: ASN (2 байта) + Выделенный номер (4 байта)
Тип 1: IP (4 байта) + Выделенный номер (2 байта)
Тип 2: ASN (4 байта) + Выделенный номер (2 байта)
Наиболее часто используемые типы RD: 0 и 1. При конфигурации на "железе", тип RD опускается.
Пример RD типа 0: "65400:200".
Пример RD типа 1: "192.0.0.1:200"
RD передается в поле NLRI атрибута MP_REACH_NRLI сообщения BGP Update, вместе с префиксом и меткой маршрута (сервисной).
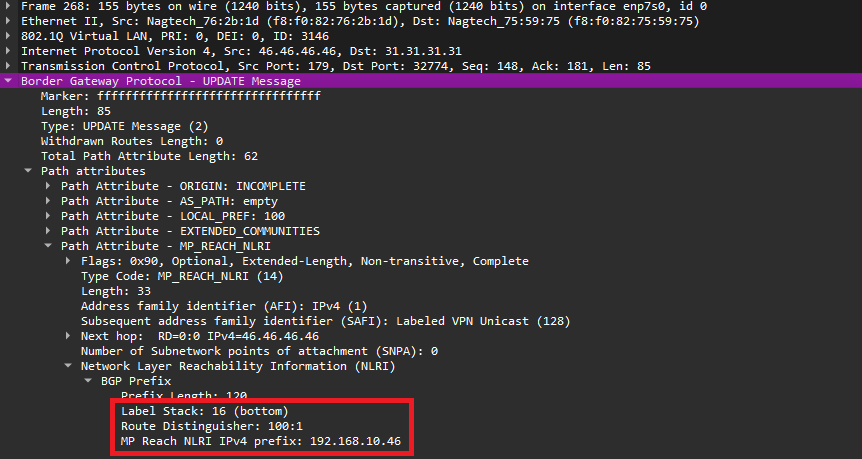
Рис. 15. Сервисная метка, RD и prefix в BGP Update сообщении
Сама транспортная метка, как и прежде, доставляется протоколами LDP или RSVP-TE, а сервисная - MBGP.
Как происходит передача VPN-префикса:
Итак:
RD НЕ является идентификатором VPN/VRF или префикса в VPN. Идентификатором префикса в VPN является сервисная метка. Единственная цель RD - сделать VPN-префикс уникальным при передаче через MP-BGP (отделить маршруты друг от друга).
RD не влияет на то, какие префиксы будут экспортированы и импортированы в тот или иной VRF.
За импорт и экспорт VPNv4-префиксов в VRF отвечает RT (Route Target).
RT (Route Target) - расширенный BGP community (extcommunity) атрибут, который управляет импортом и экспортом из MBGP в VRF. Именно он подсказывает MBGP, куда нужно передать маршрут (от англ. “target” - цель).
Формат RT точно такой же, как у обычного BGP Extended Community. Например, 65400:200.
То есть он похож на первый тип RD, и это наиболее часто используемая форма (ASN:NNN), где:
На одной стороне в VRF настраивается RT на экспорт маршрута - тот RT, с которым он будет отправлен к удаленному PE. На другой стороне это же значение RT устанавливается на импорт, и наоборот.
Export RT передается в сообщении BGP Update в атрибуте Extended_Communities. Для одного VRF может быть несколько export RT. Каждый RT может быть настроен в нескольких VRF как export. RT export определяет каким extended BGP community будет "покрашен" анонс vpvn4 при экспорте из VRF и передаче от PE1 к PE2.
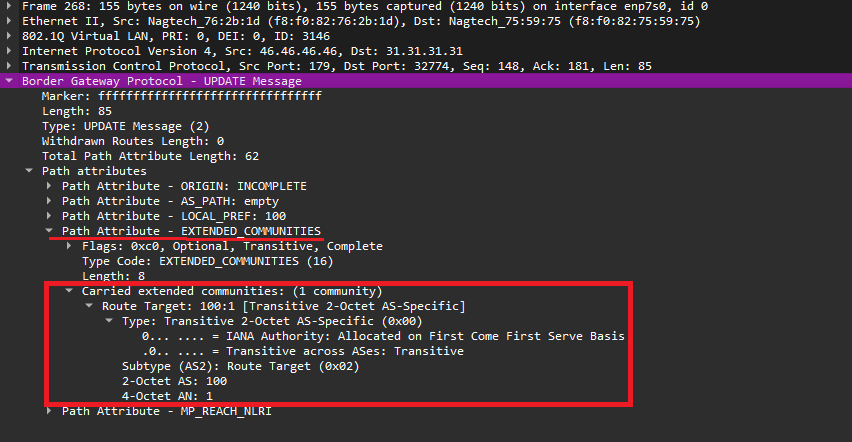
Рис. 16. Передача RT (export) в BGP Update сообщении
Import RT - локальный параметр, который определяет, какие маршруты будут импортированы в соответствующий VRF. Для одного VRF может быть несколько import RT. Каждый RT может быть настроен в нескольких VRF как import, то есть маршрут при передаче может быть экспортирован сразу в несколько VRF. RT import определяет, префикс с каким extended BGP community будет импортирован в целевой VRF.
Бывает, что нужно получить доступ из одного VPN в другой, поэтому маршруты между ними также могут импортироваться: имея разные RD, два VPN могут обмениваться маршрутами. Такая техника называется Inter-VRF Route Leaking, или может использоваться термин "перекладка маршрутов".
Еще раз обобщим про RT: в BGP атрибуте extended community передается RT на export, то есть какие маршруты могут быть экспортированы в определенный VRF. Когда маршрут прилетает на другой PE, то проверяются настройки RT import, если есть совпадение (между значением RT export в BGP Update сообщении и между значением RT import на локальном маршрутизаторе), то VPNv4-префикс переводится в IPv4 и помещается в таблицу маршрутизации соответствующего VRF, и затем анонсируется через соответствующий интерфейс далее клиенту.
В самом простом и в самом распространенном случае VRF имеет один RT на import и один RT на export, и они совпадают (хотя вполне может быть и такое, что на PE настроен RT import и из другого VRF - перекладка маршрутов, то есть RT на import и export могут быть несимметричными). К тому же, RT совпадает с RD, поэтому повторим еще раз:
Думаю, с RT и RD разобрались, в качестве небольшого итога разберем полный процесс распространения маршрутной информации (control plane) в L3VPN подробно:
1) По сети клиента маршрут распространяется по IGP, затем от клиентов CE либо через IGP, либо через eBGP маршруты приходят на PE1.
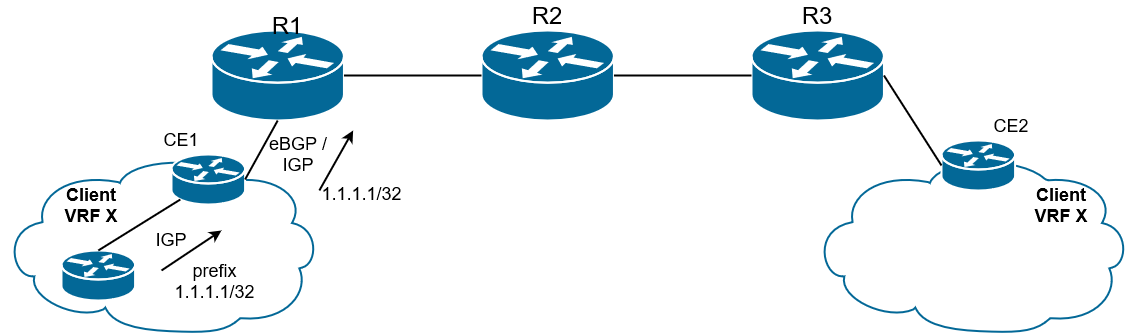
Рис. 17. Обычный IPv4-маршрут приходит от клиента на PE1
2) На основе входного интерфейса префикс помещается в VRF таблицу маршрутизации. Какой VRF будет использован, зависит от конфигурации на интерфейсе PE в сторону CE.
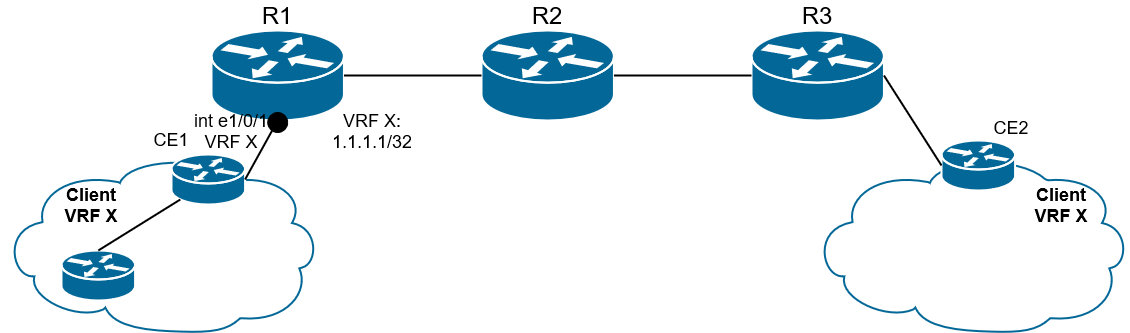
Рис. 18. IPv4-маршрут согласно интерфейсу помещается в определенный VRF
3) BGP обнаружил новый маршрут в данном VRF и импортирует его себе;
PE1 (он же R1) проверяет настройки VRF:
vrf <name>
RD ...
RT export ...
RT import ...
Из данного маршрута IPv4 PE1 компонует VPNv4-маршрут, добавляя RD (чтобы отличать данный маршрут от других), выделяет метку (сервисную, чтобы в будущем определить какому VPN предназначается трафик), вставляет RT export в секцию Extended_Communities (чтобы маршруты могли быть экспортированы в VRF). Все это берется из конфигурации VRF на PE1.
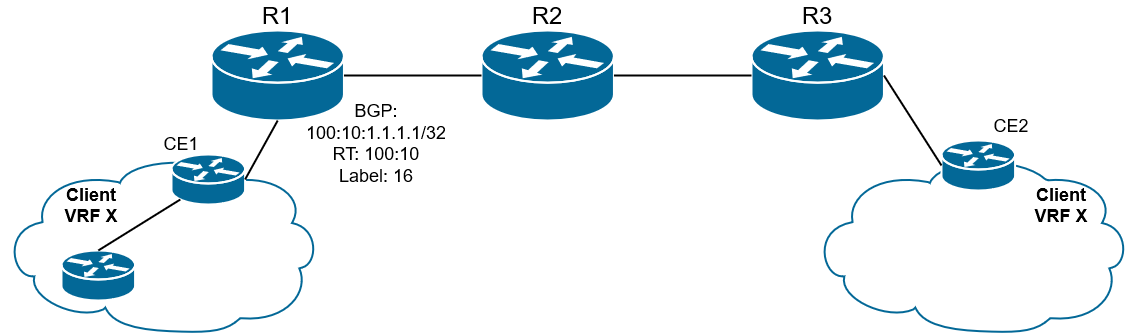
Рис. 19. IPv4-маршрут преобразуется в VPNv4-маршрут
4) Далее маршруты отправляются всем соседям (от PE к PE по MBGP) вместе с сервисной меткой.
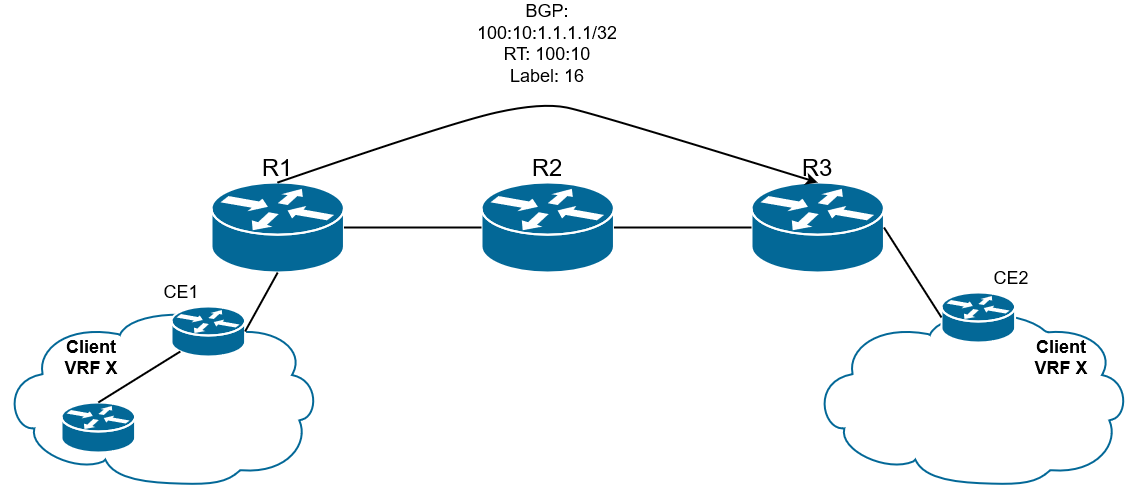
Рис. 20. VPNv4-маршрут передается по сети провайдера
Есть важный нюанс:
При анонсе VPNv4-префикса, PE всегда изменяет атрибут next-hop. Используется IP интерфейса, который указан в качестве update-source в конфигурации MBGP между PE (обычно Loopback). Это делается потому, что только PE имеет информацию, для чего использовать VPN-метку из данного анонса.
5) После того, как маршрут пришел PE-соседу, значение RT из анонса MBGP сравнивается со значением в конфигурации PE2 (RT import), так PE2 (он же R3) определяет в какой (или в какие) VRF надо импортировать маршрут.
6) RD прекращает свое существование и VPNv4-префикс конвертируется в IPv4 префикс.
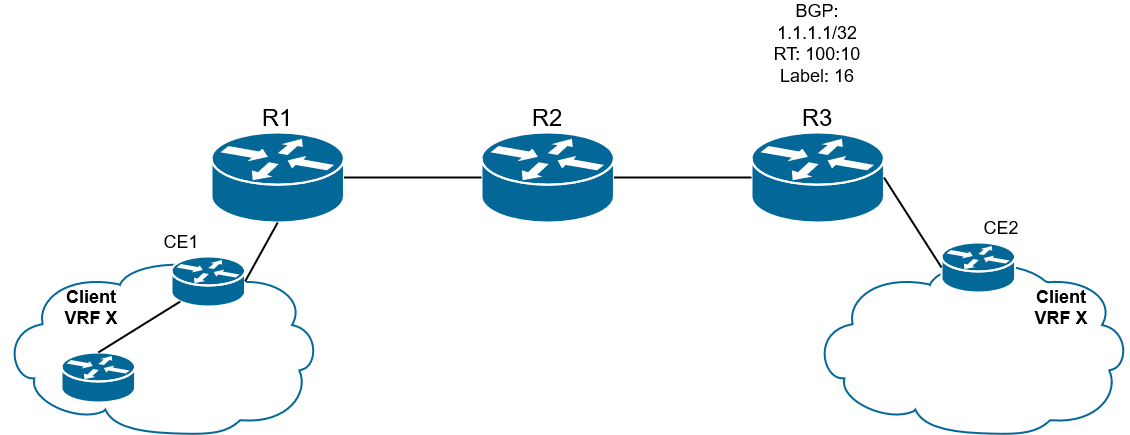
Рис. 21. VPNv4-маршрут приходит на PE2 и превращается в IPv4-маршрут
7) Маршрут на основе RT импортируется в нужный VRF, MBGP инсталлирует IPv4-префикс в таблицу маршрутизации данного VRF, а метка записывается в таблицу меток для будущего форвардинга.
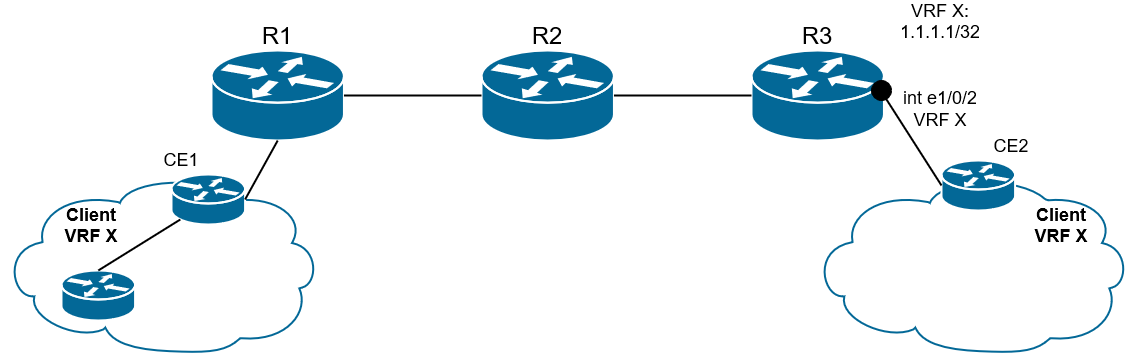
Рис. 22. После снятия RD и метки маршрут импортируется в нужный VRF
8) Далее PE2 анонсирует обычный IPv4-префикс в сторону CE по eBGP или IGP.
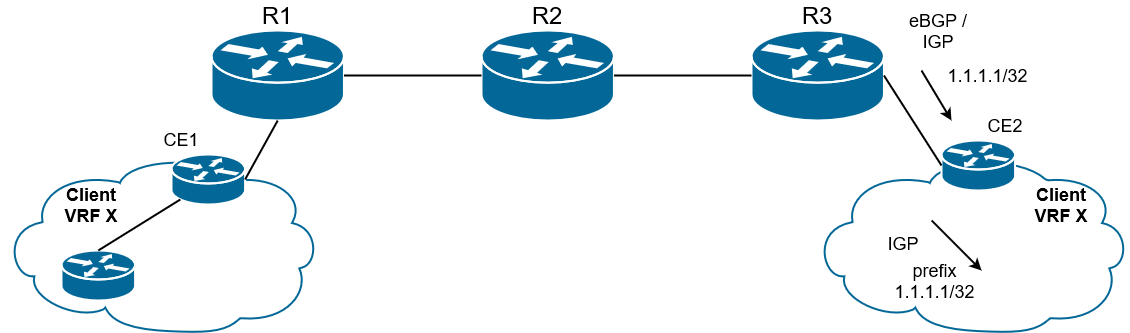
Рис. 23. Обычный IPv4-маршрут отправляется клиенту
Как правило, PE не имеют прямых MBGP стыков друг с другом. Ведь иначе пришлось бы организовывать full-mesh топологию, а это очень тяжело поддерживать и масштабировать. Обычно PE являются клиентами BGP route-reflector. Существуют некоторые особенности работы BGP route-reflector при работе с VPNv4-префиксами:
- route-reflector никогда не меняет VPN-метку и next-hop в анонсе;
- route-reflector принимает все анонсы от PE, вне зависимости от конфигурации RT.
Так мы узнаем о маршрутах. Теперь рассмотрим, для примера, как после этого будет двигаться трафик.
На PE2 в этой же схеме приходит пакет, который предназначен устройству в сети клиента за CE1. PE2 получает его на интерфейсе, который привязан к VRF. Из таблицы меток для FEC в данном VRF, мы узнаем сервисную метку. Так к пакету добавляется первый заголовок MPLS (сервисная метка). Далее смотрим таблицу маршрутизации для данного VRF, определяем так next-hop и транспортную метку, которая добавляется как второй заголовок MPLS. Далее пакет путешествует по сети, меняя верхнюю транспортную метку, в какой-то момент у нас снимается транспортная метка, и остается только сервисная. Далее PE1 смотрит на основе сервисной метке к какому VPN принадлежит данный пакет, снимает сервисную метку и отправляет IP-пакет клиенту на CE1.
Допустим, у нас точно так же идет через сеть клиентский трафик, как и в примере выше, но срабатывает механизм PHP на предпоследнем узле. Как тогда PE узнает, какая это метка: сервисная или транспортная?
Пространство меток общее. Из него метки берутся по очереди:
- транспортные (то для одного FEC, то для другого);
- сервисные (то для одного префикса VRF, то для другого).
Соответственно, если метка была выделена как сервисная, то она уже не может стать транспортной.
Итак, мы весьма подробно рассмотрели передачу маршрутной информации в MPLS L3VPN, как и коммутацию пользовательских данных, поэтому можем переходить к следующей большой теме - L2VPN.
Казалось бы, зачем нам нужен L2VPN, если, по сути, L3VPN решает необходимые задачи: обеспечение связности удаленных узлов между собой и отделение сервисов одного клиента от другого.
MPLS L3VPN позволяет построить комплексную инфраструктуру на базе сети провайдера, однако есть ситуации, при которых клиенту требуется именно L2-канал между площадками.
Например, оборудование не поддерживает IP или клиент желает полностью контролировать процесс маршрутизации в VPN.
Так или иначе возникла потребность в технологии транспортировки кадров протоколов L2 уровня через MPLS сеть провайдера.
На самом деле, могут использоваться и другие L2VPN технологии: QinQ, L2TP, VxLAN и т.д. Но именно MPLS L2VPN пользуется наибольшей популярностью среди операторов на сегодняшний день. Почему? Маршрутизаторы, передающие MPLS-пакеты могут абстрагироваться от их содержимого, но при этом различать трафик разных сервисов.
То есть не важно, что у нас передается на канальном уровне: Ethernet, ATM, HDLC и т.д., кадр будет передан в исходном его виде, даже если промежуточные маршрутизаторы ничего не знают о данной технологии, главное просто уметь вовремя сменить метку.
Возможность передавать трафик любого канального уровня в MPLS называется AToM (Any Transport over MPLS). Иногда так даже называют саму технологию MPLS L2VPN.
MPLS L2VPN бывает двух типов:
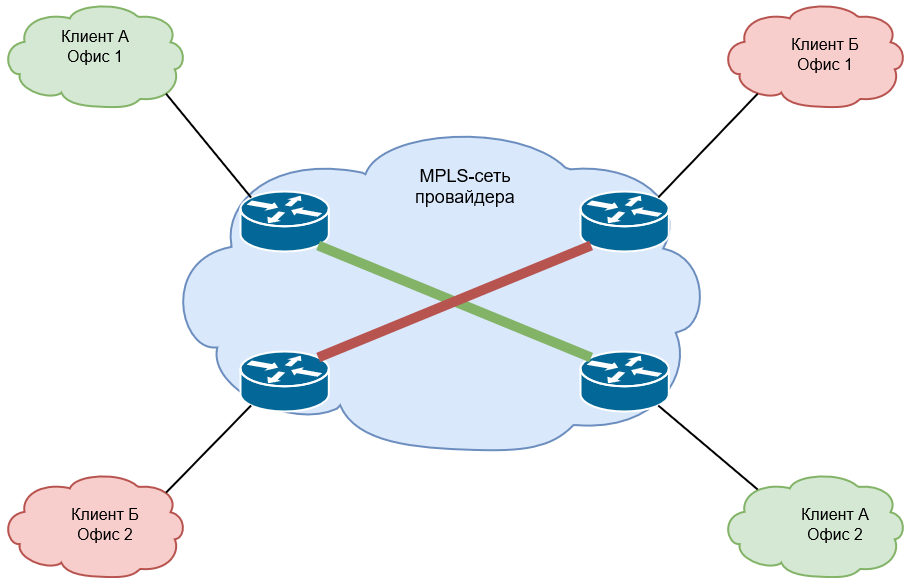
Рис. 24. Пример организации каналов точка-точка (VPWS для разных клиентов)
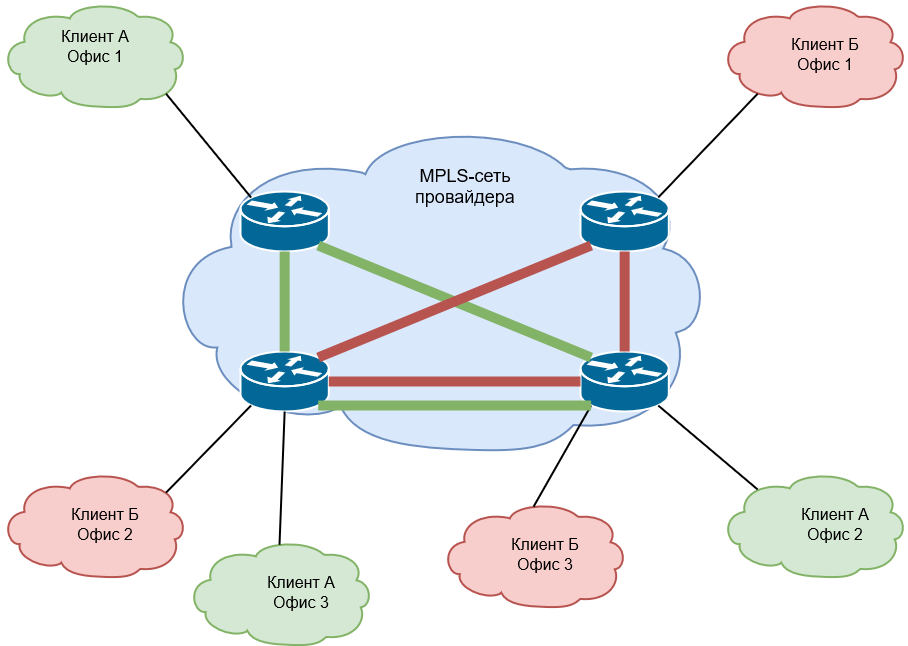
Рис. 25. Пример организации point-to-multipoint (VPLS для разных клиентов)
Начнем с разбора VPWS, но сперва немного нашей любимой терминологии.
Термины PE и CE мы уже знаем из разбора L3VPN, здесь они имеют примерно то же самое значение:
PE (Provider Edge) - граничные маршрутизаторы MPLS-сети провайдера, к которым подключаются клиентские устройства (CE).
CE (Customer Edge) - оборудование клиента, непосредственно подключающееся к маршрутизаторам провайдера (PE).
Архитектура транспорта L2-кадров через сеть пакетной коммутации (PSN - packet switched network) построена на базе виртуальных патч-кордов (pseudowire).
Pseudowire, PW (виртуальный патч-корд) - виртуальное соединение между PE-маршрутизаторами, эмулирующее провод, который передает L2-кадры.
В общем плане (термин относится не только к технологии MPLS) pseudowire - эмуляция соединения точка-точка через сеть пакетной коммутации.
Виртуальный патч-корд использует технологию туннелирования. L2-кадры инкапсулируются в MPLS-пакет. Между PE строится PSN-туннель. Внутри PSN-туннеля может быть несколько виртуальных патч-кордов, соединяющих каналы присоединения клиента (attachment circuit).
Attachment circuit, AC (канал присоединения) - физический или виртуальный канал, соединяющий CE и PE. Например, порт Ethernet, VLAN, Frame Relay DLCI, PPP-сессия.
PSN-туннель - это LSP от одного PE до другого. LSP однонаправленный, поэтому PSN-туннель состоит из двух LSP: для прямого и обратного трафика.
Внутри одного PSN-туннеля может быть несколько виртуальных патч-кордов. Чтобы идентифицировать эти патч-корды используется еще одна метка - VC-метка (virtual circuit) или PW-метка.
Virtual Circuit, VC - виртуальное однонаправленное соединение через общую сеть, имитирующее оригинальную среду для клиента. Соединяет между собой AC-интерфейсы разных PE. Pseudowire (PW) состоит из пары однонаправленных VC.
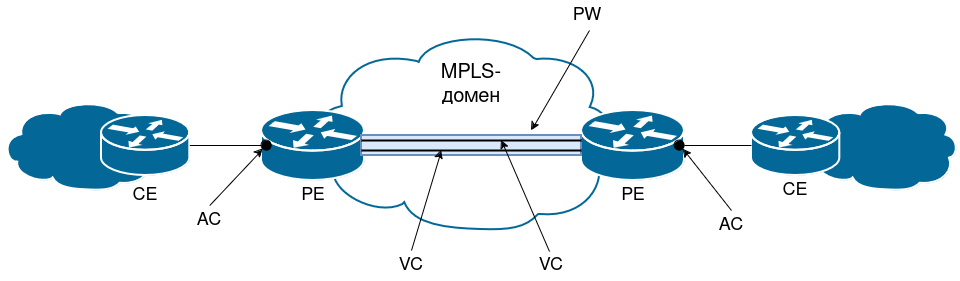
Рис. 26. Терминология MPLS L2VPN
Начнем с разбора VPWS data plane, тем более, что принцип очень похож на принцип организации работы data plane в MPLS L3VPN.
Точно так же, как и в MPLS L3VPN, существует две метки: транспортная (или туннельная) и сервисная (VPN-метка). Транспортная метка меняется на промежуточных узлах в соответствии с LFIB-таблицей, то есть осуществляет поиск next-hop, а VPN-метка находится под транспортной и является идентификатором VC (аналог VRF в L3VPN), то есть определяет, в какой AC передать пакет, в какой интерфейс.
Рассмотрим пример.
Ingress PE (PE1) получает от CE кадр (неважно какого формата и какой технологии) на AC. Данный интерфейс привязан к определенному идентификатору клиента VC ID, поэтому в соответствии с этим идентификатором PE1 навешивает на кадр VC-метку, которая будет неизменной до конца пути, а затем навешивает и туннельную метку. Туннельная метка - это метка, присвоенная IGP-префиксу, который идентифицирует Egress PE (путь LSP, как и метка у нас известны заранее). Далее MPLS-пакет распространяется от узла к узлу, в соответствии с туннельной меткой пока не достигнет Egress PE (PE2). На PE2 MPLS-пакет прилетает только с VC-меткой, туннельная метка снимается на предпоследнем хопе, срабатывает PHP (Penultimate hop popping). PE2 осуществляет поиск по LFIB, в какой канал присоединения передать L2-кадр. Снимает VC-метку и отправляет L2-кадр в нужный канал присоединения AC.
Туннельная (транспортная) метка распространяется от узла к узлу с помощью LDP, либо с помощью RSVP-TE (все как в L3VPN), а вот сервисные (VC-метки) распространяются непосредственно от PE к PE. Для этого должен использоваться специальный тип LDP сессии (ведь базовый LDP позволяет устанавливать соединение только между подключенными непосредственно напрямую друг к другу соседями), мы его уже упоминали ранее, когда разбирали механизм работы LDP, и да, это Targeted LDP. Targeted LDP может устанавливать соединение с удаленными маршрутизаторами и обмениваться с ними метками.
Сигнализация VC-меток
Targeted LDP сессия устанавливается между PE для создания и поддержания виртуальных патч-кордов. Для этого LDP был расширен новым типом FEC TLV. Основная задача Targeted LDP сессии между PE - анонс VC-меток ассоциированных с виртуальными патч-кордами. Эти метки распространяются в режиме downstream unsolicited.
Label Mapping сообщение в котором передаются VC-метки содержит два TLV:
В свою очередь FEC TLV PW ID содержит следующие элементы:
После того, как виртуальный патч-корд поднят, PE может сигнализировать о его статусе другому PE. Для этого используется два метода:
При установке виртуального патч-корда PW Status TLV добавляется к Label Mapping сообщению, это сигнализирует удаленному PE о том, что PE хочет использовать второй метод. Если удаленный PE не поддерживает PW status TLV, оба PE используют метод Label Withdraw. После установки виртуального патч-корда PW status TLV передаются в LDP сообщениях типа уведомления (Notification messages).
С VPWS все понятно и просто: организуем L2-каналы point-to-point, чтобы разные клиенты имели прямую связность между двумя своими точками (каждый только между своими). Но в этом и минус данной технологии: а что если, у клиента не две площадки, а больше, и нужно обеспечить прямую связность между всеми? Вот тут-то и появляется VPLS. Даже из названия “Virtual Private LAN Service”, LAN - подразумевает локальную сеть, а если быть точнее - это виртуальный коммутатор, соответственно помимо всего прочего возникает необходимость изучения MAC-адресов. А еще возникает необходимость в том, чтобы “виртуальные коммутаторы” и соответственно трафик разных клиентов, как обычно, не пересекался.
Но обо всем по порядку, и сперва новая порция наших любимых терминов.
VPLS-домен - изолированная виртуальная L2-сеть, то есть, грубо говоря, один отдельный L2VPN. Два разных клиента - два разных VPLS-домена.
VSI (Virtual Switching Instance) - это, грубо говоря, виртуальный коммутатор в пределах одного узла. Для каждого клиента (или сервиса) он свой. То есть трафик разных VSI (разных виртуальных коммутаторов) не может пересекаться.
VFI (Virtual Forwarding Instance) - набор структур данных, который используется для коммутации Ethernet кадров в VPLS, или идентификатор виртуального коммутатора. По сути, VSI и VFI - синонимы, поэтому мы будем использовать в будущем именно термин VFI.
VFI наполняется информацией control plane и data plane. Информация control plane - информация о принадлежности VC и VC-метках. Информация data plane - информация, полученная из процесса коммутации, например, изученные MAC-адреса.
VFI является аналогом VRF/VPN-instance в L3VPN.
VE (VPLS Edge) - узел PE, участник VPLS-домена.
В целом, процесс передачи пользовательских данных очень похож на VPWS. Однако теперь, как мы помним, существует необходимость изучения MAC-адресов и проверки MAC-таблицы при передаче трафика.
Сервис VPLS эмулирует функционал Ethernet моста:
VPLS использует MPLS-сеть как транспорт и по своей структуре похож на VPWS. По сети MPLS, от PE к PE кадры передаются по виртуальным патч-кордам, которые мультиплексируются в PSN-туннель. На PE кадры на основе VC-метки коммутируются в нужный порт или виртуальный патч-корд. Стек меток содержит две метки: верхнюю в стеке - туннельную, которая идентифицирует PSN-туннель (LSP), и нижнюю - VC-метку, которая идентифицирует виртуальный патч-корд.
Существуют определенные различия в передаче broadcast и multicast кадров в VPLS и классическом L2-коммутаторе:
Рис. 27. Пример репликации BUM-трафика после поступления кадра на AC-интерфейс
Рис. 28. Пример репликации BUM-трафика после прохода кадра через PW
Такое различие возникает из-за включенного по-умолчанию механизма расщепления горизонта (Split-horizon). В VPLS расщепление горизонта означает, что широковещательный кадр, полученный через один виртуальный патч-корд никогда не будет скоммутирован в другой виртуальный патч-корд.
Механизм расщепления горизонта совместно с полносвязной (Full-mesh) топологией гарантирует отсутствие петель в VPLS.
Для виртуальных патч-кордов в одном VFI правило расщепления горизонта действует по-умолчанию.
Рассмотрим более подробно на примере.
1) На AC-порт PE-маршрутизатора от CE пришел пользовательский кадр. PE-маршрутизатор смотрит в заголовок Ethernet и проверяет MAC-адрес отправителя.
Если данный MAC уже есть в таблице MAC-адресов данного VFI, PE сразу переходит к следующему шагу. Если этого адреса еще нет, то PE записывает соответствие MAC-порт в таблицу и также переходит к следующему шагу.
2) PE-маршрутизатор смотрит в заголовок Ethernet и проверяет MAC-адрес получателя
3) Удаленный PE после получения кадра и снятия меток (то есть когда уже определил VFI) тоже действует как обычный коммутатор:
Как и в обычном коммутаторе записи в MAC-таблице VFI периодически устаревают и удаляются.
В вопросе изучения MAC-адресов в VPLS есть один нюанс: PE должен не просто знать физический порт, откуда пришел кадр - важно определить соседа или, точнее, PW как виртуальный интерфейс. Дело в том, что клиентский кадр нужно отправить не просто в какой-то физический порт, а именно в правильный PW, иными словами, правильному соседу.
Для этой цели каждому соседу выдается личная метка, с которой тот будет отправлять кадр этому PE в данном VPLS-домене.
И в дальнейшем по VPN-метке, заглянув в LFIB, PE узнает, от какого соседа пришел кадр.
Как мы уже выяснили ранее, для VPLS требуется полносвязная топология PE для каждого VFI. Причем не все PE MPLS-сети провайдера будут соседями, а только те, где есть этот VFI.
Поэтому один из главных вопросов в VPLS - обнаружение всех PE, куда подключены клиенты данного VFI.
Сигнализация VPLS
В VPLS существует два подхода к сигнализации (для обмена сервисными метками и MAC-адресами):
Первый подход был предложен Cisco, а именно сотрудником Luca Martini, поэтому у данного метода есть название: “Martini mode”. VPLS Martini mode описан в RFC 4762.
Второй подход был предложен Juniper, сотрудником Kireeti Kompella. Соответственно данный подход получил название “Kompella mode”. VPLS Kompella mode описан в RFC 4761.
Martini mode или сигнализация с помощью LDP по принципу работы аналогичен сигнализации в VPWS. Что же касается Kompella mode или сигнализации с помощью BGP, то данный метод мы не будем рассматривать подробно, это весьма непростая тема, по которой можно написать еще одну условную статью, к тому же данный метод НЕ используется на коммутаторах SNR: на всех актуальных моделях коммутаторов SNR с поддержкой MPLS на текущий момент поддерживается только VPLS Martini mode. Поэтому если есть желание самостоятельно разобраться как функционирует VPLS Kompella mode, можно обратиться все к тем же “Сетям для самых маленьких” или к выше упомянутому RFC 4761.
Разберем лишь поверхностно принципы работы и отличия данных методов друг от друга.
Сигнализация с помощью LDP
Принцип работы данного метода такой же, как и в сигнализации VPWS.
Задача, которую решает этот метод - распространение информации о VC-метках между PE посредством установки Targeted-LDP сессии.
При использовании LDP сигнализации информация о VC-метках распространяется только в пределах пары PE, между которыми установлена Targeted-LDP сессия. Необходимо вручную конфигурировать виртуальные патч-корды на каждой паре PE принадлежащей к одному экземпляру VPLS.
Достоинства данного метода:
Недостатки:
Сигнализация и автообнаружение PE с помощью BGP
Другие названия VPLS Kompella mode - VPLS Auto-Discovery или VPLS BGP Signaling.
Control Plane выполняет здесь две основные функции:
Обнаружение соседей или Auto-Discovery происходит аналогично L3VPN, с помощью extcommunity - Route Target и определенных Address family.
При использовании BGP сигнализации информация о VC-метках принимается всеми PE, принадлежащими к одному экземпляру VPLS.
Так как iBGP маршрутизаторы имеют полную связанность, либо получают информацию о метках от route reflector’ов.
Достоинства метода:
Недостатки:
Несмотря на свои некоторые преимущества, Kompella mode является менее популярным, чем Martini mode. И как мы уже сказали, на коммутаторах SNR поддерживается именно Martini mode, но об этом мы еще поговорим.
Для транспортировки Ethernet кадров через MPLS могут использоваться два режима инкапсуляции данных:
1) Режим VLAN (“Tagged mode”).
В режиме VLAN канал присоединения - 802.1Q VLAN. При распространении VC-меток значение используется PW-Type 4 (0x0004).
2) Режим порта (“Raw mode”).
В режиме порта канал присоединения - Ethernet порт. При распространении VC-меток используется значение PW-Type 5 (0x0005).
Чем же конкретно отличаются данные режимы инкапсуляции?
Когда PE получает Ethernet кадр, и этот кадр имеет тег VLAN, мы можем выделить два сценария:
Является тег служебно-разграничительным или нет, определяется локальной конфигурацией PE.
Если PW работает в Raw mode, теги для разделения услуг никогда НЕ передаются через PW. Если тег разделения услуг присутствует, когда кадр получен из AC на PE, он ДОЛЖЕН быть удален из кадра перед отправкой кадра в PW.
Если PW работает в Tagged mode, каждый кадр, отправляемый по PW, ДОЛЖЕН иметь тег VLAN, разграничивающий услуги. Если кадр, полученный на PE от AC, не имеет тега VLAN, разграничивающих услуги, PE должен добавить к кадру фиктивный (временный) тег VLAN перед отправкой кадра на PW.
В обоих режимах (Raw/Tagged) теги, НЕ разграничивающие сервисы (non service-delimiting), прозрачно передаются через PW как часть полезных данных. И нужно также учитывать, что в одном Ethernet кадре может быть больше одного тега, и как минимум, один из них в теории может быть service-delimiting, но в любом случае, провайдер должен анализировать только самый верхний тег для применения (определения) кадра к виртуальному патч-корду.
В обоих режимах теги разграничивающие сервисы (service-delimiting) имеют только локальное значение, т. е. имеют смысл только на конкретном интерфейсе PE-CE.
При использовании Tagged mode, PE, который получает кадр от PW, может перезаписать значение тега, может полностью удалить тег или оставить тег неизменным, в зависимости от его конфигурации. В режиме Tagged по виртуальному патч-корду могут передаваться кадры только одного VLAN. При этом не обязательно, чтобы теги VLAN совпадали с двух сторон виртуального патч-корда.
Когда используется Raw mode, PE, который получает кадр, может добавлять или не добавлять тег разделения услуг перед передачей кадра в AC, однако он НЕ ДОЛЖЕН перезаписывать или удалять уже существующие теги. В режиме Raw по виртуальному патч-корду можно передать кадры, принадлежащие к нескольким VLAN, так же как они передаются в trunk-портах между L2-коммутаторами.
Таблица ниже иллюстрирует операции, которые могут быть выполнены при поступлении кадра с AC на PE:
Таблица 2
Описание инкапсуляции Ethernet кадров в MPLS
| Тег |
Service delimiting (разделяющий сервисы) |
Non service delimiting (не разделяет сервисы, поступил от клиента) |
|---|---|---|
| Raw mode | Удалить тег (верхний), инкапсулировать кадр в MPLS пакет, отправить в PW | Операции не выполняются: инкапсулировать кадр в MPLS пакет, отправить в PW |
| Tagged mode | Либо не выполнять операции, либо добавить тег, либо перезаписать тег на тот, который ожидается на другой стороне согласно конфигурации, инкапсулировать кадр в MPLS пакет, отправить в PW | Добавить service delimiting тег (фиктивный), который ожидается на другой стороне согласно конфигурации, инкапсулировать кадр в MPLS пакет, отправить в PW |
Подробно процесс инкапсуляции Ethernet в MPLS описан в RFC 4448.
Из текущего модельного ряда коммутаторов SNR поддержка MPLS есть на следующих моделях:
Сперва рассмотрим характеристики и особенности этих моделей.

Рис. 29. SNR-S300G-24FX
Модель SNR-S300G-24FX представляет собой высокопроизводительное решение для уровня агрегации и ядра. Комбинация оптических и медных GE интерфейсов, 10GE uplink порты, широкий L2 и L3 функционал - все это позволяет применять коммутаторы серии S300G для решения широкого спектра задач как в сетях операторов связи, так и в корпоративных сетях.
Таблица 3
Обзор характеристик SNR-S300G-24FX
| Характеристики | SNR-S300G-24FX |
|---|---|
| Интерфейсы | 16x 10/100/1000Base-T | 100/1000Base-X SFP, 8x 100/1000Base-X SFP, 4x 1/10G SFP+, 2x 20G QSFP+ (только для стекирования) |
| Матрица коммутации | 208 Gbps |
| Скорость пересылки пакетов | 155 Mpps |
| Jumbo frame | 16 кбайт |
| Таблица MAC | 32K (standard) / 40K (route) / 64K (bridge) |
| Размер таблицы маршрутизации (IPv4/IPv6) | 16K/6K |
| Количество маршрутов PIM (IPv4/IPv6) | 308/308 |
| Размер таблицы ARP (IPv4/IPv6) | 16K/16K |
| Пакетный буфер | 4 МБ |
| Кол-во IGMP групп | 1K |
| ACL | 3K |
| Количество MPLS меток | 8K |
| Количество VFI | 256 |
| Количество VRF Instance | 251 |

Рис. 30. SNR-S4650X-48FQ
Коммутатор SNR-S4650X-48FQ - это высокопроизводительное устройство нового поколения, предназначенное для применения на уровне агрегации и ядра сети или в качестве TOR коммутаторов в дата-центрах.
Таблица 4
Обзор характеристик SNR-S4650X-48FQ
| Характеристики | SNR-S4650X-48FQ |
|---|---|
| Интерфейсы | 48x 1/10G SFP+, 6x 40G QSFP+ |
| Матрица коммутации | 1440 Gbps |
| Скорость пересылки пакетов | 1071 Mpps |
| Jumbo frame | 12 кбайт |
| Таблица MAC | 96K (standard) / 32K (route) / 288K (bridge) |
| Размер таблицы маршрутизации (IPv4/IPv6) | 16K/8K |
| Количество маршрутов PIM (IPv4/IPv6) | 4K/4K |
| Размер таблицы ARP (IPv4/IPv6) | 16K/16K |
| Пакетный буфер | 12 МБ |
| Кол-во IGMP групп | 8K |
| ACL | 1K |
| Количество MPLS меток | 8K |
| Количество VFI | 256 |
| Количество VRF Instance | 64 |

Рис. 31. SNR-S7550C-32F
Серия коммутаторов S7550 - это высокопроизводительные устройства самого нового поколения, предназначенные для применения на уровне агрегации и ядра сети или в ЦОД. И данная серия на текущий момент представлена двумя моделями, обе с поддержкой MPLS, VxLAN и MC-LAG.
Таблица 5
Обзор характеристик SNR-S7550Y-48C и SNR-S7550C-32F
| Характеристики | SNR-S7550Y-48C | SNR-S7550C-32F |
|---|---|---|
| Интерфейсы | 48x 10/25G SFP28, 6x 40/100G QSFP28 | 32x 40/100G QSFP28 |
| Матрица коммутации | 3600 Gbps | 6400 Gbps |
| Скорость пересылки пакетов | 2600 Mpps | 4700 Mpps |
| Jumbo frame | 9 кбайт | 9 кбайт |
| Таблица MAC | 40K (standard) / 8K (route) / 104K (bridge) | 40K (standard) / 8K (route) / 104K (bridge) |
| Размер таблицы маршрутизации (IPv4/IPv6) | 32K/8K | 32K/8K |
| Количество маршрутов PIM (IPv4/IPv6) | 4K/4K | 4K/4K |
| Размер таблицы ARP (IPv4/IPv6) | 32K/16K | 32K/16K |
| Пакетный буфер | 16 МБ | 16 МБ |
| Кол-во IGMP групп | 8K | 8K |
| ACL | 768 | 768 |
| Количество MPLS меток | 8K | 8K |
| Количество VFI | 256 | 256 |
| Количество VRF Instance | 1023 | 1023 |
Процесс настройки и диагностики, как и ранее в теоретической части, мы начнем с настройки базового MPLS.
Но стоит сперва сразу уточнить, что коммутаторы SNR поддерживают только Martini mode (VPWS Martini, VPLS Martini), то есть обмен сервисными метками с помощью протокола tLDP. В качестве метода работы с метками в последнем пролете всегда используется Implicit NULL (механизм PHP, то есть последний коммутатор в MPLS домене получает трафик уже без метки) - это аппаратное ограничение.
Возьмем для примера такую схему сети:
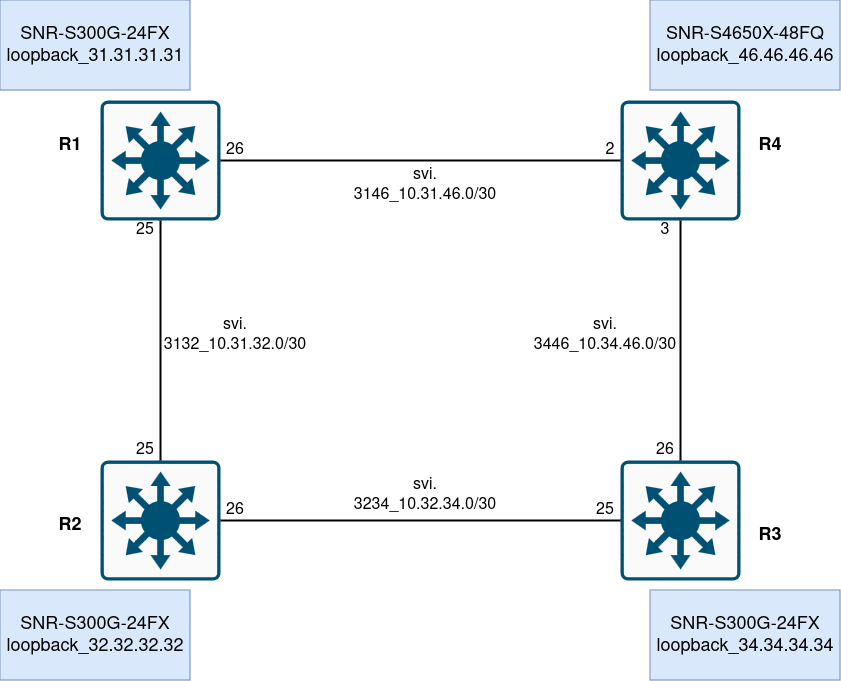
То есть, у нас будет своя условная сеть провайдера уровня агрегация-ядро, которая представляет из себя кольцевую топологию, а в основе этой сети, как мы видим, стоят 3 коммутатора SNR-S300G-24FX и один SNR-S4650X-48FQ.
Как мы уже знаем, для того, чтобы MPLS смог обмениваться информацией о метках, сперва нам нужно, чтобы работала маршрутизация, то есть чтобы все узлы в сети, имели маршрутную информацию о своих сетях и сетях соседей.
Поэтому прежде всего настроим IGP маршрутизацию, а именно - OSPF.
Выполним такую конфигурацию
На R1:
mtu 12000
!
vlan 3132
name svi.3132_10.31.32.0/30
!
vlan 3146
name svi.3146_10.31.46.0/30
!
Interface Ethernet1/0/25
description S300G_32.32.32.32_int_e1/0/25
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3132
!
Interface Ethernet1/0/26
interface mode cr
description S4650X_46.46.46.46_int_e1/0/2
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3146
!
interface Vlan3132
mtu 2000
ip address 10.31.32.1 255.255.255.252
!
interface Vlan3146
mtu 2000
ip address 10.31.46.1 255.255.255.252
!
interface Loopback1
ip address 31.31.31.31 255.255.255.255
!
router ospf 1
ospf router-id 31.31.31.31
network 10.31.32.0/30 area 0
network 10.31.46.0/30 area 0
network 31.31.31.31/32 area 0
redistribute connected
!
router bgp 10
bgp router-id 31.31.31.31
neighbor 32.32.32.32 remote-as 10
neighbor 32.32.32.32 update-source Loopback1
neighbor 34.34.34.34 remote-as 10
neighbor 34.34.34.34 update-source Loopback1
neighbor 46.46.46.46 remote-as 10
neighbor 46.46.46.46 update-source Loopback1
!
На R2:
mtu 12000
!
vlan 3132
name svi.3132_10.31.32.0/30
!
vlan 3234
name svi.3234_10.32.34.0/30
!
Interface Ethernet1/0/25
description S300G_31.31.31.31_int_e1/0/25
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3132
!
Interface Ethernet1/0/26
description S300G_34.34.34.34_int_e1/0/25
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3234
!
interface Vlan3132
mtu 2000
ip address 10.31.32.2 255.255.255.252
!
interface Vlan3234
mtu 2000
ip address 10.32.34.1 255.255.255.252
!
interface Loopback1
ip address 32.32.32.32 255.255.255.255
!
router ospf 1
ospf router-id 32.32.32.32
network 10.31.32.0/30 area 0
network 10.32.34.0/30 area 0
network 32.32.32.32/32 area 0
redistribute connected
!
router bgp 10
bgp router-id 32.32.32.32
neighbor 31.31.31.31 remote-as 10
neighbor 31.31.31.31 update-source Loopback1
neighbor 34.34.34.34 remote-as 10
neighbor 34.34.34.34 update-source Loopback1
neighbor 46.46.46.46 remote-as 10
neighbor 46.46.46.46 update-source Loopback1
!
На R3:
mtu 12000
!
vlan 3234
name svi.3234_10.32.34.0/30
!
vlan 3446
name svi.3446_10.34.46.0/30
!
Interface Ethernet1/0/25
description S300G_32.32.32.32_int_e1/0/26
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3234
!
Interface Ethernet1/0/26
interface mode cr
description S4650X_46.46.46.46_int_e1/0/3
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3446
!
interface Vlan3234
mtu 2000
ip address 10.32.34.2 255.255.255.252
!
interface Vlan3446
mtu 2000
ip address 10.34.46.1 255.255.255.252
!
interface Loopback1
ip address 34.34.34.34 255.255.255.255
!
router ospf 1
ospf router-id 34.34.34.34
network 10.32.34.0/30 area 0
network 10.34.46.0/30 area 0
network 34.34.34.34/32 area 0
redistribute connected
!
router bgp 10
bgp router-id 34.34.34.34
neighbor 31.31.31.31 remote-as 10
neighbor 31.31.31.31 update-source Loopback1
neighbor 32.32.32.32 remote-as 10
neighbor 32.32.32.32 update-source Loopback1
neighbor 46.46.46.46 remote-as 10
neighbor 46.46.46.46 update-source Loopback1
!
На R4:
mtu 12000
!
vlan 3146
name svi.3146_10.31.46.0/30
!
vlan 3446
name svi.3446_10.34.46.0/30
!
Interface Ethernet1/0/2
interface mode cr
description S300G_31.31.31.31_int_e1/0/26
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3146
!
Interface Ethernet1/0/3
interface mode cr
description S300G_34.34.34.34_int_e1/0/26
switchport discard packet untag
switchport mode trunk
switchport trunk allowed vlan 3446
!
interface Vlan3146
mtu 2000
ip address 10.31.46.2 255.255.255.252
!
interface Vlan3446
mtu 2000
ip address 10.34.46.2 255.255.255.252
!
interface Loopback1
ip address 46.46.46.46 255.255.255.255
!
router ospf 1
ospf router-id 46.46.46.46
network 10.31.46.0/30 area 0
network 10.34.46.0/30 area 0
network 46.46.46.46/32 area 0
redistribute connected
!
router bgp 10
bgp router-id 46.46.46.46
neighbor 31.31.31.31 remote-as 10
neighbor 31.31.31.31 update-source Loopback1
neighbor 32.32.32.32 remote-as 10
neighbor 32.32.32.32 update-source Loopback1
neighbor 34.34.34.34 remote-as 10
neighbor 34.34.34.34 update-source Loopback1
!
Помимо OSPF заранее настроили обычный iBGP, BGP нам пригодится в дальнейшем при рассмотрении MPLS L3VPN, а также сразу же на всякий случай выставили максимальный L3MTU на всех SVI.
Посмотрим, что OSPF соседства поднялись:




Как видим, все хорошо, все соседи видят друг друга, все в состоянии Full, то есть обменялись своими LSDB. И поскольку Router priority не устанавливались вручную, и по умолчанию равны 1, то роли DR/BDR выбраны верно (по наибольшему Router-ID).
Проверим также на всякий случай, что BGP-сессии тоже поднялись:
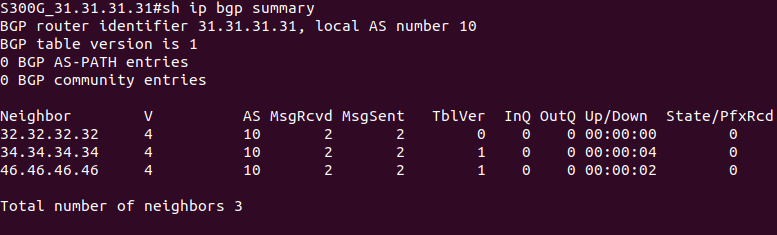
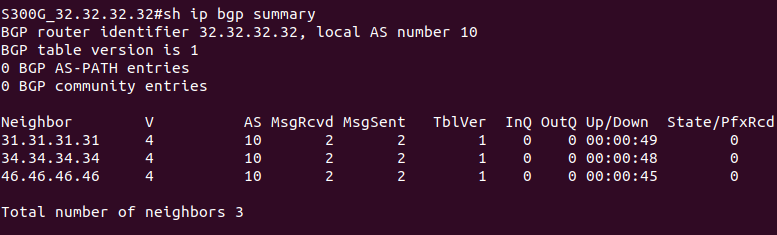
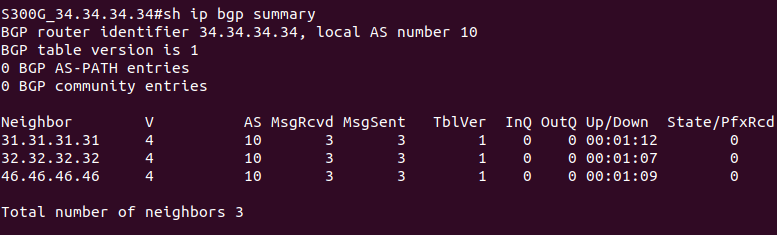
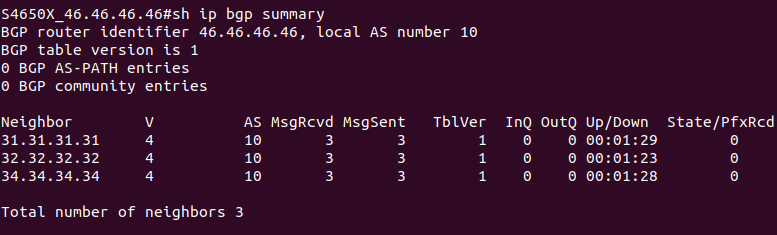
И проверим таблицы маршрутизации:
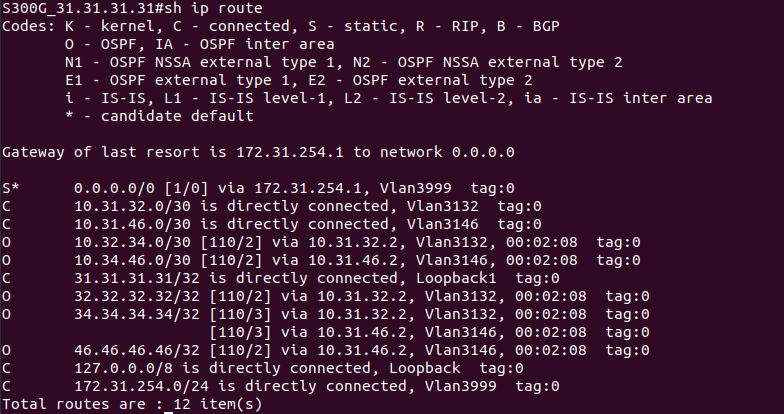
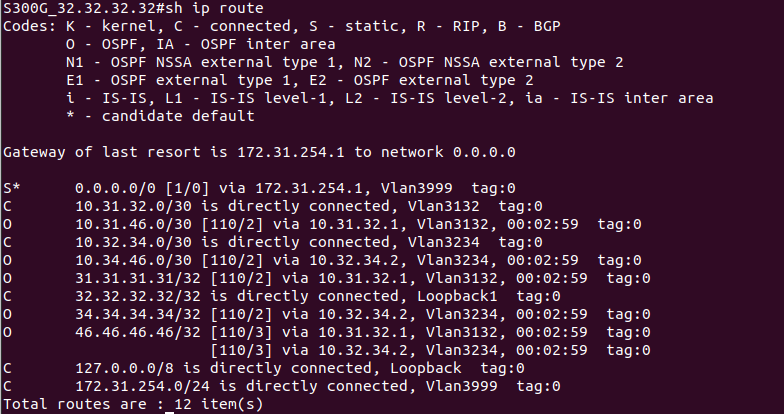
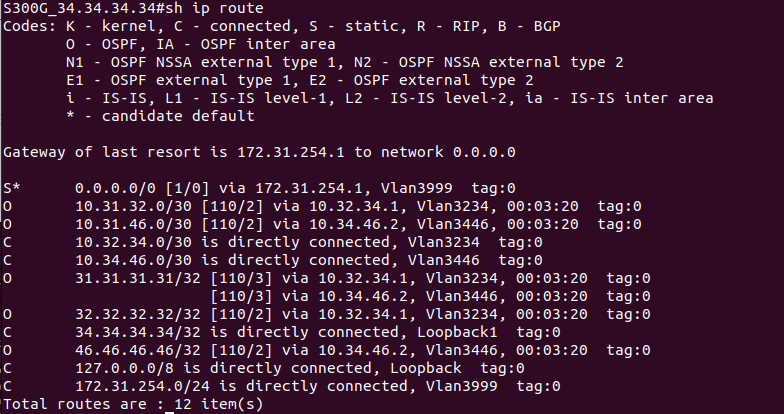
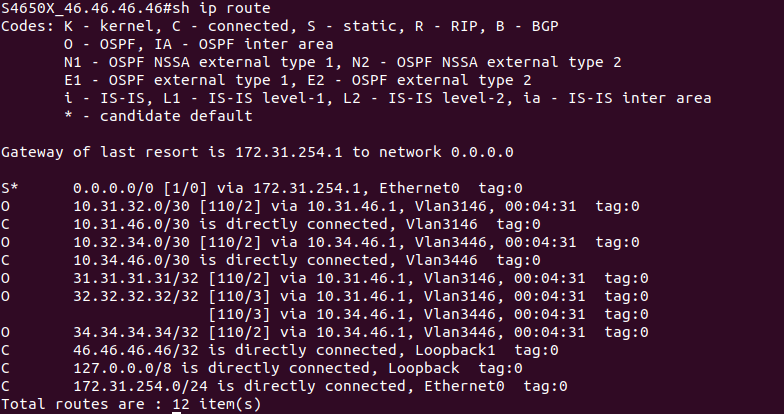
Как видим, маршруты есть до каждой сети. Причем на всех коммутаторах до одной из сетей (loopback-адрес соседа, который не подключен к ним напрямую) в таблицу маршрутизации попало два маршрута. Дело в том, что если маршрутизатор (или L3-коммутатор) изучает два (или более) маршрута через один и тот же протокол маршрутизации до одной и той же сети (одинаковый адрес и одинаковая маска подсети), с одинаковой метрикой, то оба маршрута будут добавлены в таблицу маршрутизации. Трафик будет балансироваться между этими маршрутами с помощью ECMP (Equal Cost Multi-Path). Но, как говорится, есть нюанс: ECMP для LDP на данный момент на коммутаторах SNR не реализован, и как распределяются метки и строится LSP мы разберем чуть позже.
Перейдем непосредственно к настройке базового MPLS.
В данной статье мы рассмотрим только самые необходимые и часто используемые команды в процессе настройки, поскольку команд, связанных с MPLS очень большое количество, и в целом, они все интуитивно понятны или подробно описаны в command guide или configuration guide, но если все равно что-то останется непонятным, то, разумеется, вы всегда сможете оставить свой вопрос на nag.support.
Команды мы будем применять на одном узле, но понятно, что конфигурация на остальных узлах будет симметрична.
Сперва нужно включить MPLS глобально:
S300G_31.31.31.31(config)#mpls ?
egress-ttl Specify a TTL value for LSPs for which this LSR is the egress
enable Forward MPLS protocol packet
ingress-ttl Specify a TTL value for LSPs for which this LSR is the ingress
local-packet-handling Enable labeling of locally generated TCP packets
S300G_31.31.31.31(config)#mpls enable ?
<cr>
Затем, учитывая, что у нас уже настроена маршрутизация и существуют необходимые SVI, нам необходимо настроить только LDP.
Включаем LDP на SVI:
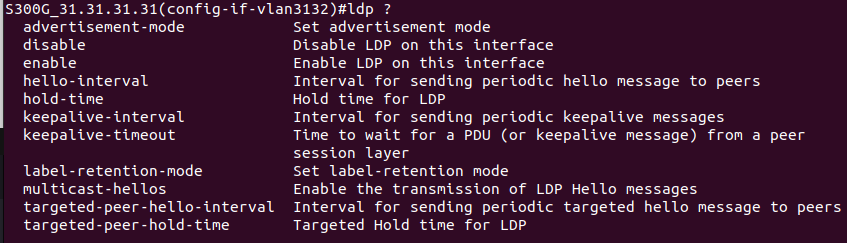
S300G_31.31.31.31(config-if-vlan3132)#ldp enable ?
<cr>
S300G_31.31.31.31(config-if-vlan3132)#label-switching ?
<cr>
В этом же разделе мы можем настроить режим отправки меток - “advertisement-mode” (downstream-on-demand | downstream-unsolicited), можем настроить интервалы отправки таймеров LDP для Hello пакетов, keepalive и т.д.
Затем включаем LDP глобально (режим конфигурации процесса LDP):
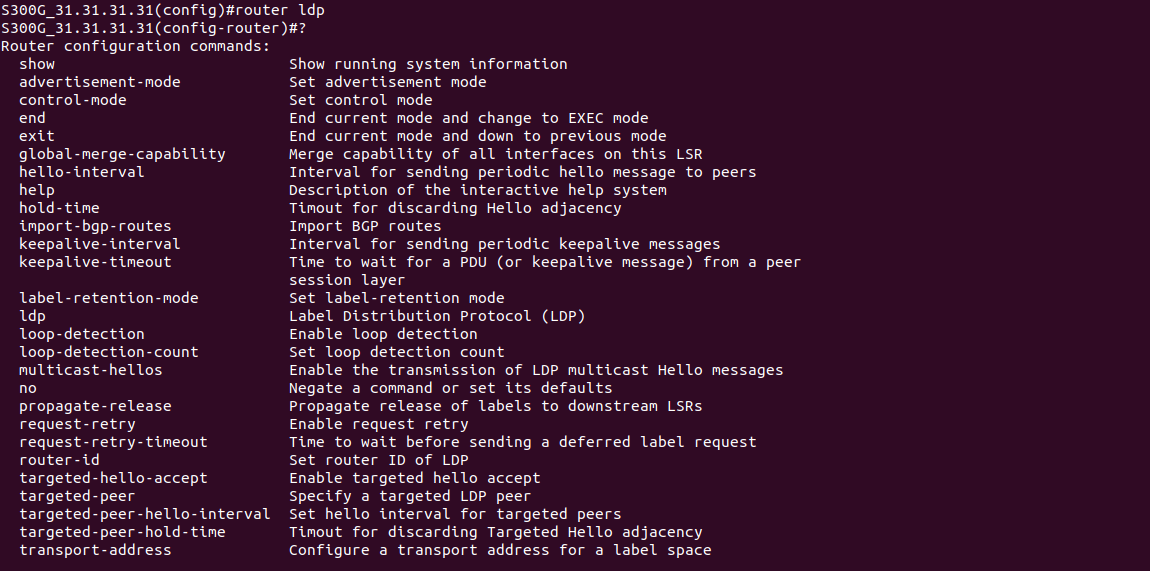
S300G_31.31.31.31(config)#router ldp ?
<cr>
Настраиваем LDP router-ID:
S300G_31.31.31.31(config)#router ldp
S300G_31.31.31.31(config-router)#router-id ?
A.B.C.D LDP router ID value
S300G_31.31.31.31(config-router)#router-id 31.31.31.31 ?
<cr>
Указываем в качестве транспортного адреса - адресацию на Loopback1 интерфейсе, который мы уже создали ранее:
S300G_31.31.31.31(config-router)#transport-address ?
A.B.C.D IPv4 Address of a loopback interface
S300G_31.31.31.31(config-router)#transport-address 31.31.31.31 ?
<cr>
В этом же режиме конфигурации также можем настроить различные параметры для работы LDP.
Возможно, вы заметили, что в конфигурации касаемо LDP на SVI и в самом LDP процессе, есть схожие настройки (например, касаемо таймеров). Настройки LDP в режиме конфигурации SVI будут иметь приоритет над глобальными настройками LDP.
Отметим еще такую настройку как:
S300G_31.31.31.31(config-router)#ldp ?
route route
tcp-connection Enable tcp connection
S300G_31.31.31.31(config-router)#ldp route ?
redistribute-host-only redistribute-max-prefix
redistribute-list redistribute list
По умолчанию на коммутаторах SNR анонсируются метки для всех FEC, но это можно изменить следующими командами: с помощью ‘redistribute-host-only' будут анонсироваться метки только для loopback-адресов, а с помощью ‘redistribute-list’ можно и вовсе указать определенный access-list.
Это необязательная настройка, но она может помочь уменьшить нагрузку на устройства и сеть и сократить кол-во используемых меток.
Итак, необходимые настройки для базового MPLS выполнены, аналогичные настройки выполняется на остальных коммутаторах, после этого коммутаторы начинают обмен LDP сообщениями, где устанавливают между собой соседские отношения, обмениваются метками, поддерживают сессию:
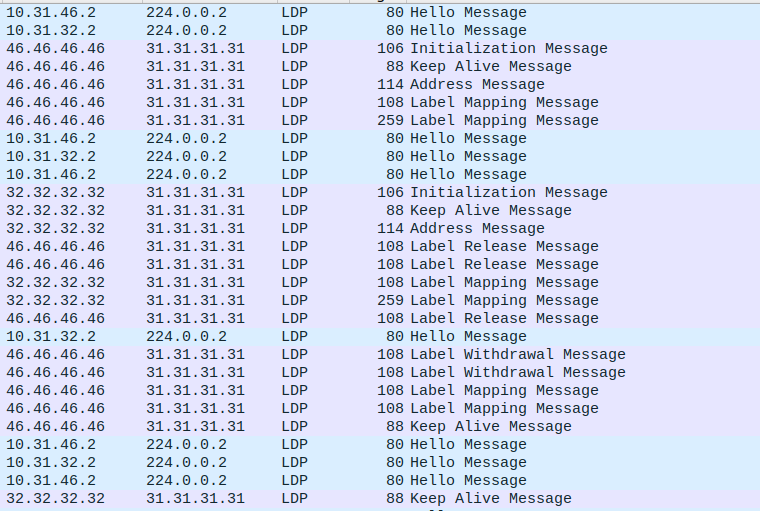
После этого будет сформирована LFIB-таблица:
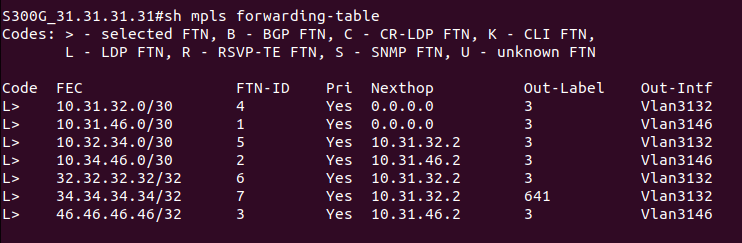
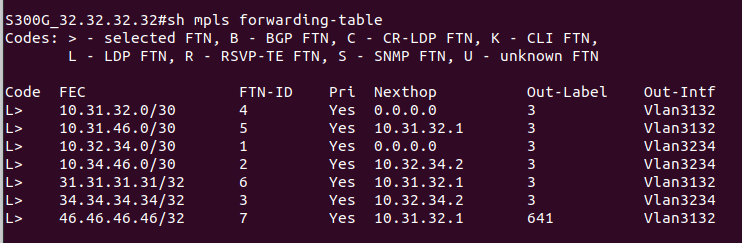
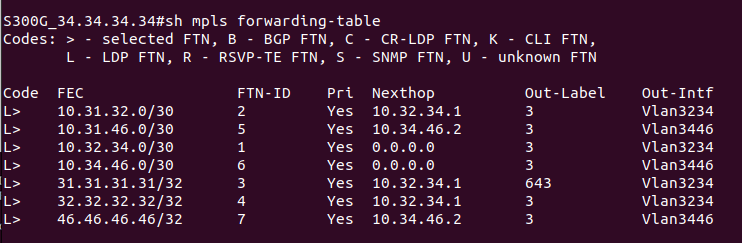
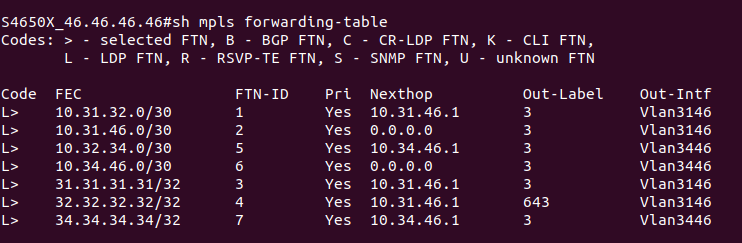
Поскольку у нас кольцевая топология состоящая всего из 4 коммутаторов, и поскольку на коммутаторах SNR используется метод implicit-null, поэтому практически везде out-label для каждого FEC - 3. Но где-то используются и другие метки, для FEC, которые находятся не напрямую подключенном узле.
Данные метки передаются в LDP Label Mapping сообщении.
LFIB таблица формируется на основе других таблиц, ну или, по крайней мере, тесно связана с ними.
Например, FTN-table.
S300G_31.31.31.31#sh mpls ftn-table ?
brief Brief information
detail Detail information
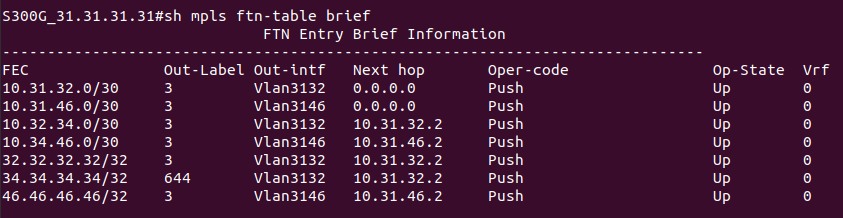
FTN = FEC to NHLFE
NHLFE = Next Hop Label Forwarding Entry - описывает выполняемую операцию над меткой, используется для пересылки пакетов MPLS.
То есть данная таблица указывает соответствие между FEC и NHLFE. Каждая запись в этой таблице определяет правило, которое будет применяться к входящим пакетам, и действие, которое необходимо применить для соответствующих пакетов.
С помощью опции detail соответственно можно посмотреть более подробную информацию.
Incoming Label Map (ILM) - определяет соответствие входящей метки к NHLFE, то есть какое действие выполнять с входящей меткой.
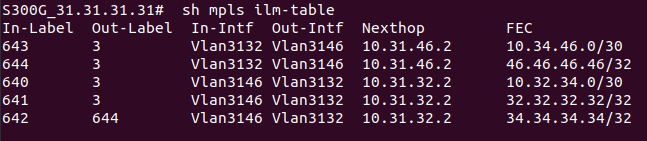
К примеру, на данный узел приходит пакет с меткой 641, и он предназначен FEC 32.32.32.32/32, в таком случае будет выполнен механизм PHP, и пакет будет отправлен на next-hop 10.31.32.2. Или если на узел приходит пакет с меткой 642 для FEC 34.34.34.34/32, тогда необходимо заменить метку на 644 и отправить пакет на next-hop.
И последняя таблица, которую хочется упомянуть - LDP FEC:
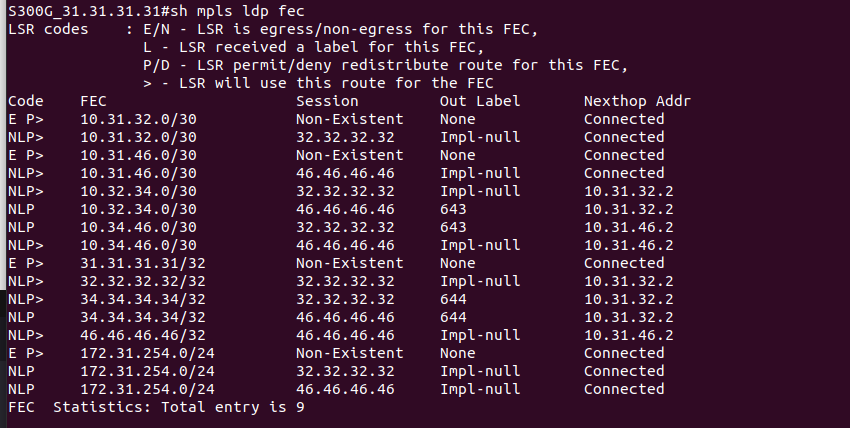
В данной таблице содержится информация обо всех FEC для данного устройства, и для каждого FEC может быть больше одного маршрута, и как мы уже знаем, в LFIB-таблицу попадет только один.
Теперь рассмотрим пример настройки MPLS L3VPN.
Конфигурация у нас будет похожа на предыдущую из раздела настройки базового MPLS, однако теперь мы добавим настройки VRF с указанием RD и RT (настройки ниже с R1, но на остальных коммутаторах конфигурация симметрична):
ip vrf L3VPN_test
rd 100:1
route-target both 100:1
Создали еще один Loopback интерфейс, который будет принадлежать данному VRF:
interface Loopback2
ip vrf forwarding L3VPN_test
ip address 192.168.10.31 255.255.255.255
!
Немного перенастроили BGP-процесс, в том числе активировали передачу префиксов и сервисных меток для них через BGP и включили редистрибуцию маршрутов из VRF, чтобы можно было передавать static и connected VRF маршруты:
router bgp 10
bgp router-id 31.31.31.31
redistribute connected
redistribute static
neighbor 32.32.32.32 remote-as 10
neighbor 32.32.32.32 update-source Loopback1
neighbor 34.34.34.34 remote-as 10
neighbor 34.34.34.34 update-source Loopback1
neighbor 46.46.46.46 remote-as 10
neighbor 46.46.46.46 update-source Loopback1
address-family vpnv4 unicast
neighbor 32.32.32.32 activate
neighbor 34.34.34.34 activate
neighbor 46.46.46.46 activate
exit-address-family
address-family ipv4 vrf L3VPN_test
redistribute connected
redistribute static
exit-address-family
Ну и добавили возможность пинговать локальные интерфейсы с помощью команды ‘mpls local-packet-handling’.
Настроили клиентов из одного VRF:
Клиент1:
interface Vlan3001
ip vrf forwarding L3VPN_test
ip address 192.168.31.1 255.255.255.0
!
Interface Ethernet1/0/9
switchport access vlan 3001
!
Клиент2:
interface Vlan3000
ip vrf forwarding L3VPN_test
ip address 192.168.30.4 255.255.255.0
!
Interface Ethernet1/0/9
switchport access vlan 3000
!
Смотрим таблицу маршрутизации, но там о данных маршрутах ни слова: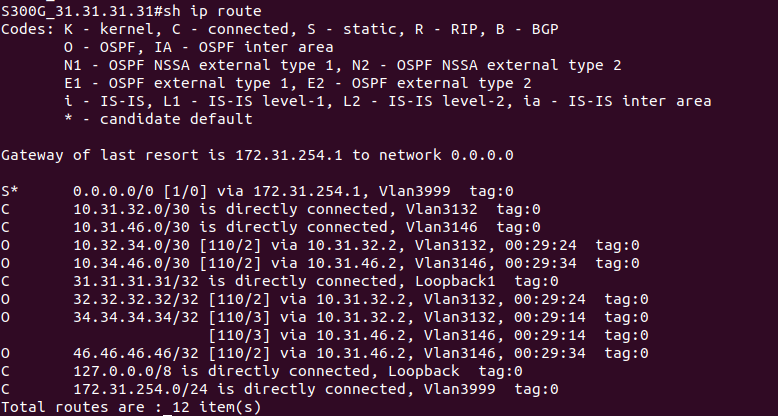
Все потому, что нужно смотреть таблицу маршрутизации конкретно для данного VRF, там наши новые маршруты есть: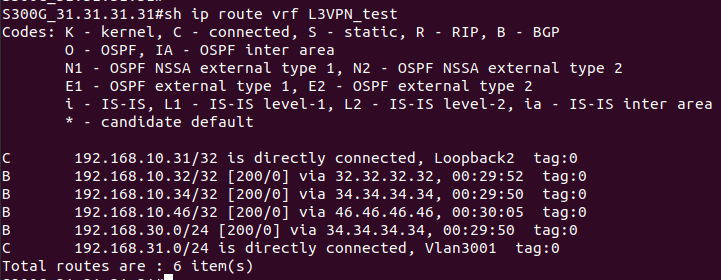
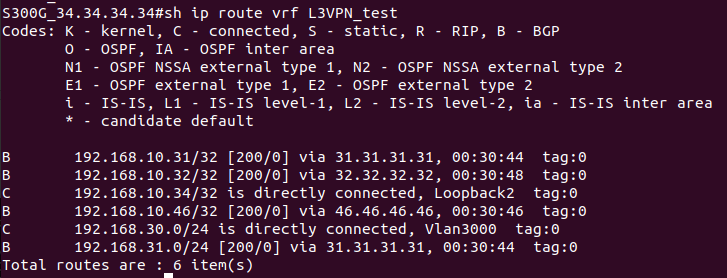
Посмотрим BGP-таблицу для нашего VRF: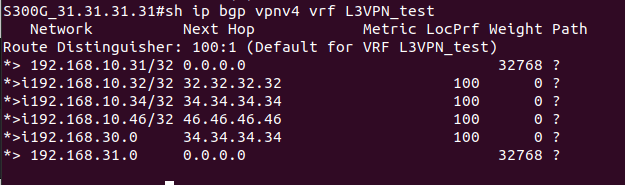
И таблицу коммутации MPLS: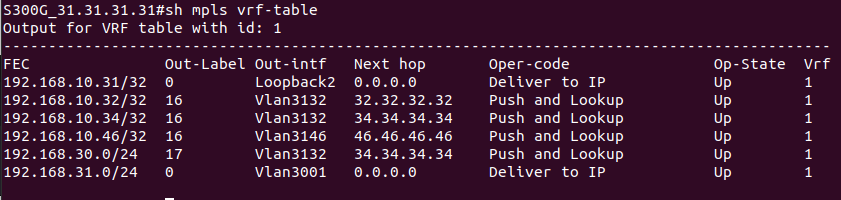
И на другом узле: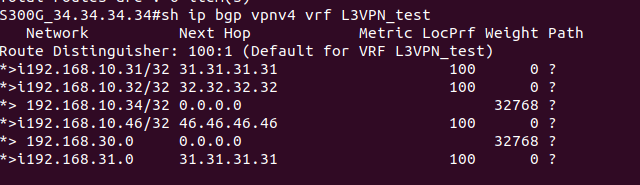
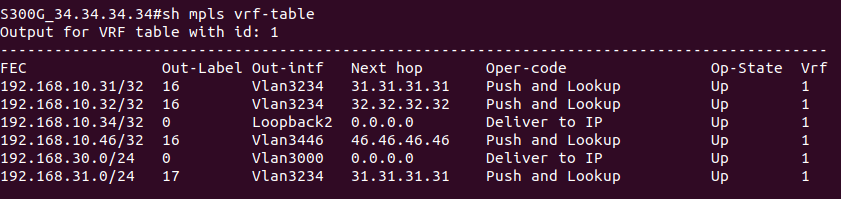
В выводе ‘sh ip bgp vpnv4 vrf L3VPN_test’ мы видим, что все VPN-префиксы доступны нам по BGP, причем какие-то локально, а какие-то через next-hop.
В выводе ‘sh mpls vrf-table’ мы видим таблицу коммутации. Для префиксов, которые доступны локально, для них метка 0, потому что чтобы достичь этот префикс, нужно просто отправить пакет на свой интерфейс, без каких-либо дополнительных меток (действие “Deliver to IP”).
Для префиксов, которые доступны через next-hop назначена определенная выходная метка, то есть требуется добавить заголовок MPLS с данной меткой и отправить его в соответствующий интерфейс (действие “Push and Lookup”).
Для всех префиксов код VRF - 1, это просто порядковый номер VRF, которые созданы на коммутаторе.
Посмотрим, как происходил обмен маршрутной информацией на примере одного узла:
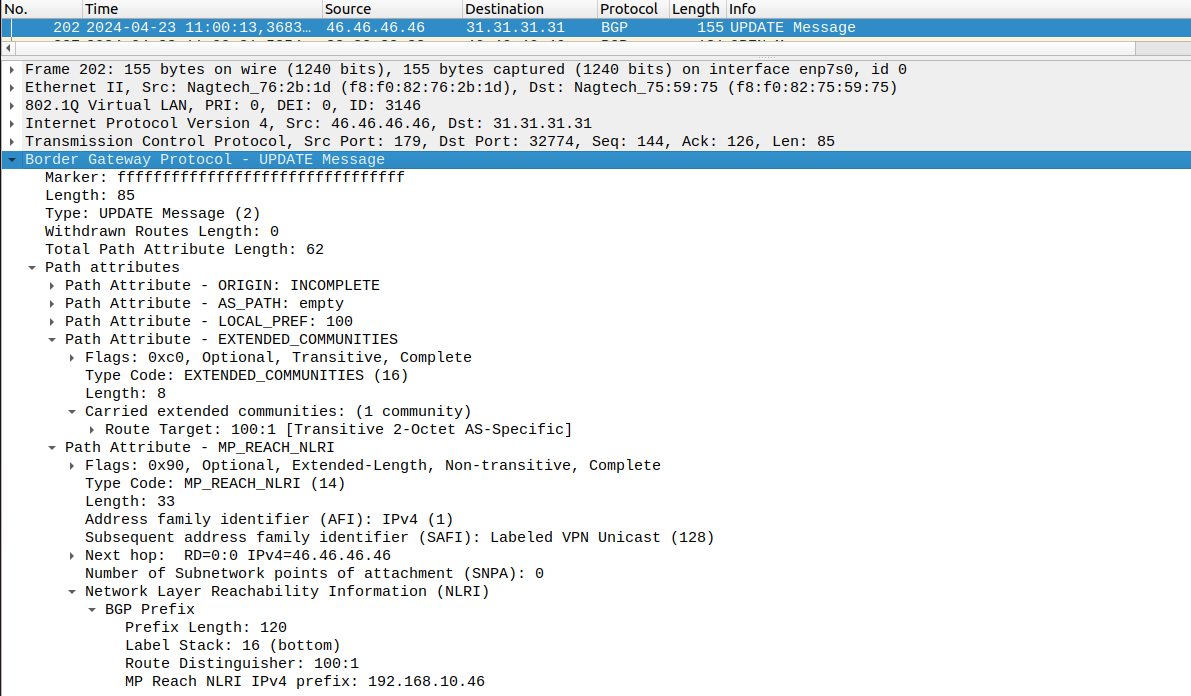
Здесь мы видим как в MBGP (секция “MP_REACH_NLRI”) передается информация о префиксе: сам префикс, RD, метка для данного префикса и RT. То же самое происходит и с другими префиксами и на других узлах. Именно так происходит обмен маршрутной информацией и обмен сервисными метками в MPLS.
Проверим связность между клиентами:
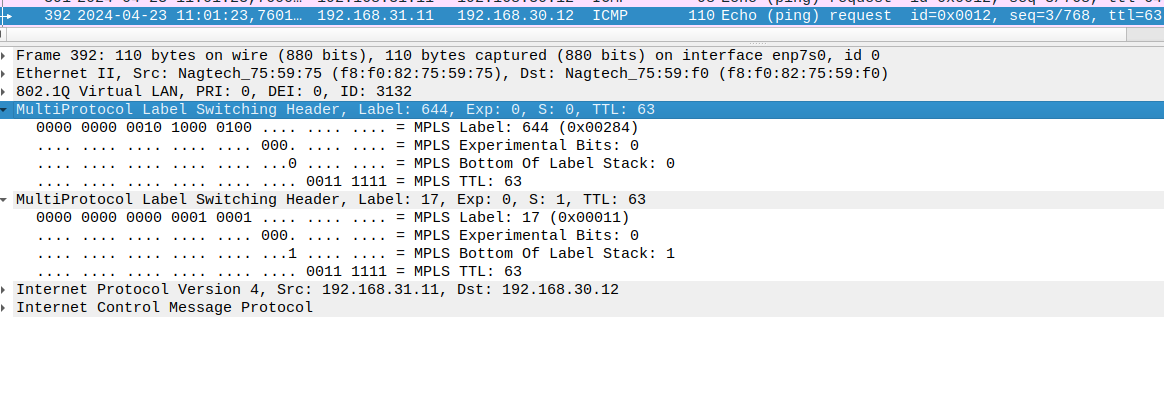
Поскольку эти дампы мы получили не без помощи мониторинговой сессии, то в ICMP request мы видим две MPLS метки: и сервисную, и транспортную. А вот в сообщении ICMP reply мы видим уже только сервисную метку (та же самая 17 метка, того же самого VRF), т.к. транспортная была по всей видимости обработана механизмом PHP.
Как вы уже заметили, мы подключили двух “клиентов” на узлах 31.31.31.31 и 34.34.34.34 соответственно. Они находятся в одном VRF, но при этом про VRF они ничего не знают. Данные “клиенты” имеют адресацию из разных подсетей, и нам даже необязательно пробрасывать их VLAN по всей нашей сети, связность между двумя точками клиента все равно есть, в этом и есть преимущество MPLS. Аналогично мы можем создать другой VRF на двух концах сети, и трафик данных клиентов будет передаваться в пределах одного VRF, будет еще одна своя таблица маршрутизации для этого VRF, причем адресацию можно использовать такую же, что мы использовали в VRF L3VPN_test, и при этом их трафик никак не будет взаимодействовать между собой. Все мы это уже обсуждали в теоретической части.
Настройка VPWS
Поскольку нам необходимо установить сессию между узлами, подключенными не напрямую, чтобы мы могли обмениваться сервисными метками, нам необходимо использовать tLDP (тот самый Martini mode).
Поэтому в уже привычной нам конфигурации в режиме конфигурации LDP процесса необходимо явно прописать удаленные пиры:
router ldp
router-id 31.31.31.31
targeted-peer 34.34.34.34
!
После этого коммутаторы начнут периодически отправлять tLDP Hello сообщения:
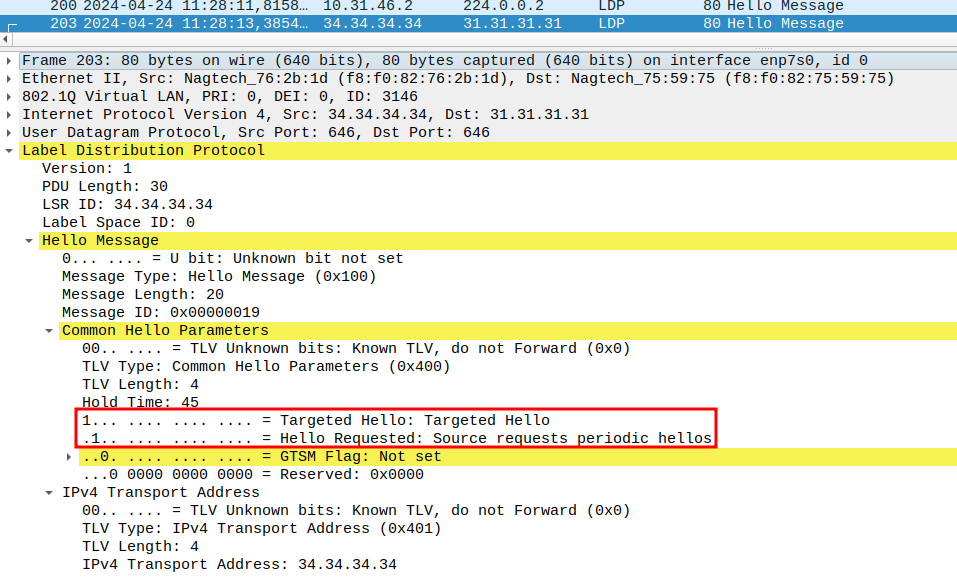
Добавим и остальные настройки для работы VPWS.
Создадим pw-class:
S300G_31.31.31.31(config)#pw-class ?
NAME Identifying string for pw-class,<1-32> characters
S300G_31.31.31.31(config)#pw-class VPWS_class_test_1
И создадим l2-vc:
S300G_31.31.31.31(config)#l2-vc ?
A.B.C.D IP address of the peer node to be added
S300G_31.31.31.31(config)#l2-vc 34.34.34.34 ?
pw-id Virtual-Circuit Identifier
S300G_31.31.31.31(config)#l2-vc 34.34.34.34 pw-id ?
<1-4294967295> Indentifier
S300G_31.31.31.31(config)#l2-vc 34.34.34.34 pw-id 100 ?
group-id Group identifier
mtu Set VFI configured MTU
pw-class PW Class
<cr>
S300G_31.31.31.31(config)#l2-vc 34.34.34.34 pw-id 100 pw-class ?
NAME Class Name
S300G_31.31.31.31(config)#l2-vc 34.34.34.34 pw-id 100 pw-class VPWS_class_test_1
В режиме конфигурации порта присваиваем l2-vc физическому интерфейсу:
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect ?
l2-vc L2-vc
vfi Virtual forwarding instance
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc ?
pw-id Virtual-Circuit Identifier
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id ?
<1-4294967295> Indentifier<1-4294967295>
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id 100 ?
mode Access mode
<cr>
Сейчас мы уже можем применить команду, и тогда все, что будет отправляться в данный порт (точнее с данного порта, на OUT), будет инкапсулировано в MPLS и отправлено в туннель, потому что это поведение по умолчанию, но можно дополнительно и указать явно, что будет отправлено в туннель, то есть настроить “режимы доступа” к туннелю:
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id 100 mode ?
ethernet Ethernet mode
vlan Vlan mode
Режим доступа "ethernet" направляет в MPLS-туннель все пакеты, которые приходят на порт (на OUT). Это и есть поведение по умолчанию, про которое мы говорили.
Режим доступа "vlan" направляет в туннель только те пакеты, которые приходят с тегом VLAN, указанным далее в команде: ‘... svid <VLAN ID>’:
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id 100 mode vlan ?
svid service instance
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id 100 mode vlan svid ?
<1-4094> service instance ID
Но нам сейчас это не особо принципиально, поскольку у нас в качестве клиентского оборудования используется на какой-либо CE-маршрутизатор, а просто конечное устройство, поэтому в качестве примера выберем ethernet, просто потому что нам так хочется:
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect l2-vc pw-id 100 mode ethernet ?
<cr>
Конфигурация с другой стороны симметрична (в том числе и по указанию tLDP-соседа).
Посмотрим как происходит обмен метками:
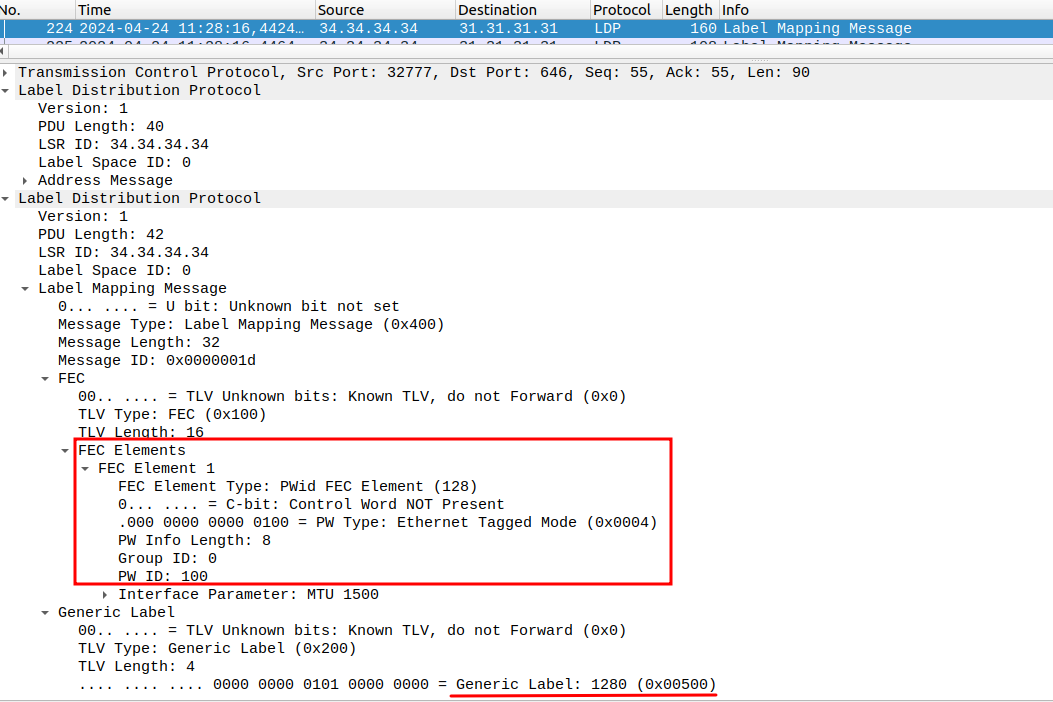
В данном дампе нас интересует FEC Element Type, здесь его значение - “PWid FEC Element (120)”. К примеру, при обмене метками в базовом MPLS или в MPLS L3VPN, тип FEC Element Type: “Prefix FEC (2)”. Это еще раз говорит нам о том, что в MPLS L2VPN провайдер никак не участвует в распространении и обработке маршрутной информации, здесь строго L2-уровень, и в качестве FEC здесь выступают идентификаторы туннелей - pw-id. Значение же самого pw-id (его идентификатор) также передается в данном сообщении.
Проверим состояние l2-vc:

Думаю, в данном выводе все максимально понятно.
Проверим связность между двумя удаленными точками:

Связность есть, и еще раз обратим внимание на то, что поскольку это L2VPN, то в MPLS пакете у нас два заголовка Ethernet: один являются частью клиентского кадра и остается неизменным, а второй меняется в процессе передачи пакета по MPLS сети.
Настройка VPLS
Аналогично настройке VPWS, сперва нам нужно указать tLDP пиры:
router ldp
router-id 31.31.31.31
targeted-peer 32.32.32.32
targeted-peer 34.34.34.34
transport-address 31.31.31.31
!
S300G_31.31.31.31(config)#pw-class ?
NAME Identifying string for pw-class,<1-32> characters
S300G_31.31.31.31(config)#pw-class VPLS_test_class_1
Ранее при разборе VPWS мы не рассматривали варианты настройки в режиме конфигурации самого pw-class, хотя тут тоже есть на что обратить внимание:
S300G_31.31.31.31(config-pw-class)#?
pw-class configuration commands:
show Show running system information
end End current mode and change to EXEC mode
exit End current mode and down to previous mode
help Description of the interactive help system
no Negate a command or set its defaults
transport-mode Set VPLS PW transport mode
Думаю, вы уже поняли, что нас интересует настройка “transport-mode”
S300G_31.31.31.31(config-pw-class)#transport-mode ?
ethernet Ethernet transport mode
vlan Vlan transport mode
Если вы еще не догадались, что это, то подсказка: мы уже рассматривали это в теоретической части. И да, это режимы инкапсуляции пакетов: те самые Raw mode и Tagged mode.
Рассмотрим подробно реализацию на коммутаторах SNR, и возможности этого функционала и примеры использования в комбинации с другими командами.
Итак, выше в теории мы уже рассматривали режимы инкапсуляции пакетов: Raw mode (на коммутаторах SNR - это Ethernet mode) и Tagged mode (на коммутаторах SNR - это VLAN mode).
Также при разборе VPWS мы упоминали режимы доступа к туннелю, и там тоже есть mode ethernet и mode vlan.
На всякий случай, проясним явно, что это разный функционал и, к примеру, ethernet mode в режиме инкапсуляции пакетов и ethernet mode в режиме доступа к туннелю - это разные вещи. Еще раз: режимы инкапсуляции определяют будет ли к пакету добавлен тег VLAN при передаче по сети MPLS, а режиме доступа в принципе определяют - будет ли помещен тот или иной пакет в MPLS туннель.
Но для более полного понимания, мы рассмотрим, как этот функционал может работать вместе. Чтобы не запутаться в терминах, режимы инкапсуляции будем так и называть: Raw mode и Tagged mode, а режимы доступа будем называть: Ethernet access и VLAN access.
Проще рассматривать это, разделив передачу данных по направлению относительно туннеля: на Input (то есть пакет пришел от CE на PE, и сейчас пакет на входе перед туннелем) и на Output (пакет направляется от PE к CE, то есть пакет находится на выходе из туннеля). Для примера будем использовать VLAN 777. Вся информация далее по инкапсуляции MPLS (снятие/добавление тега при передаче через туннель) касается только верхнего тега 802.1Q (например, если в пакете больше одного тега 802.1Q).
Input:
Output:
По умолчанию используется режим инкапсуляции VLAN mode, его мы и оставим.
Продолжим настройку VPLS.
Создадим и настроим VFI (наш виртуальный коммутатор):
S300G_31.31.31.31(config)#vfi ?
NAME Identifying string for VFI
S300G_31.31.31.31(config)#vfi VPLS_test ?
<1-4294967295> Identifying value for VFI
<cr>
S300G_31.31.31.31(config)#vfi VPLS_test 200
Посмотрим, что есть в режиме конфигурации VFI:
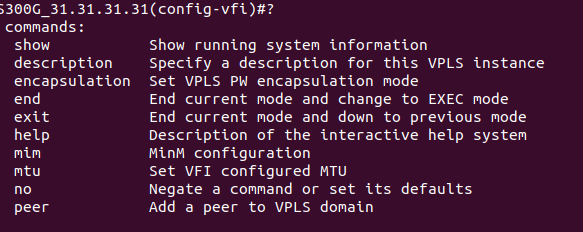
‘encapsulation’ - команда, аналогичная ‘transport-mode’ из конфигурации pw-id:
S300G_31.31.31.31(config-vfi)#encapsulation ?
ethernet Ethernet encapsulation mode
vlan Vlan encapsulation mode
Команда в данном режиме имеет более высокий приоритет, чем ‘transport-mode’ из режима конфигурации pw-id. По умолчанию используется режим “VLAN”.
Далее добавим наших пиров в VPLS-домен (точнее в наш виртуальный коммутатор):
S300G_31.31.31.31(config-vfi)#peer ?
A.B.C.D IP address of the peer node to be added
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 ?
no-split-horizon No Split Horizon
pw-class PW Class
pw-id Virtual-Circuit Identifier
<cr>
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 pw-id ?
<1-4294967295> Indentifier
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 pw-id 200 ?
no-split-horizon No Split Horizon
pw-class PW Class
<cr>
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 pw-id 200 pw-class ?
CLASS-NAME Class Name
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 pw-id 200 pw-class VPLS_test_class_1 ?
<cr>
Как вы могли обратить внимание, для виртуального коммутатора можно отключить расщепление горизонта (split horizon):
S300G_31.31.31.31(config-vfi)#peer 32.32.32.32 no-split-horizon ?
pw-class PW Class
<cr>
Но с этим нужно быть осторожнее, сейчас мы этого делать не будем.
Аналогично добавим и остальных пиров, конфигурация VFI получится следующая:
S300G_31.31.31.31(config-vfi)#show ru c
!
vfi VPLS_test 200
peer 32.32.32.32 pw-id 200 pw-class VPLS_test_class_1
peer 34.34.34.34 pw-id 200 pw-class VPLS_test_class_1
!
Осталось привязать xconnect к физическому интерфейсу:
S300G_31.31.31.31(config)#int e1/0/9
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect vfi ?
<1-4294967295> Virtual forwarding instance ID <1-4294967295>
Как и в случае с VPWS, в режиме конфигурации порта при указании xconnect мы можем указать: все ли пакеты будут отправлены в наш виртуальный коммутатор (ethernet mode), либо только с определенным тегом (vlan mode).
S300G_31.31.31.31(config-if-ethernet1/0/9)#xconnect vfi 200 mode ?
ethernet Ethernet mode
vlan Vlan mode
Проверяем, что у нас получилось:

Посмотрим, какую еще информацию можно посмотреть по VPLS:
S300G_31.31.31.31#sh vpls ?
NAME Identifying string for VPLS
detail Show detailed VPLS information
fib Show VPLS fib information
peer Peer
| Output modifiers
<cr>

Думаю, что здесь также все прозрачно понятно.

И уже привычная нам LFIB-таблица, но для VPLS.
Все три точки имеют связь друг с другом, значит наш виртуальный коммутатор работает корректно.
Наверняка вы заметили, что метки для разных сервисов начинают распределяться с определенных значений (чисел). Дело в том, что на коммутаторах SNR существует несколько диапазонов (блоков) меток. Если метки из одного блока заканчиваются, то начнут расходоваться метки из другого блока. Например, для разных сервисов по умолчанию уже распределены определенные диапазоны меток: публичные транспортные метки для базового MPLS (для LDP) имеют свой диапазон: от 640 до 1279. Сервисные метки для L3VPN находятся в диапазоне от 16 до 639, а сервисные метки для L2VPN (и VPLS, и VPWS) находятся в диапазоне от 1280 до 1879. И если, к примеру, из блока сервисных меток для L3VPN доступные для использования метки закончатся, то коммутатор задействует другой диапазон, условно от 1880 до 2479, если закончатся метки и из этого блока, то будет задействован следующий блок и т.д.
В данной статье мы постарались подробно рассмотреть для чего же вообще в наши дни нужен MPLS, принцип его работы и реализацию на коммутаторах SNR. Материал получился очень объемным, и понятно, что все нюансы рассмотреть не удастся, но мы постарались донести информацию максимально полно и с пользой. В любом случае, если у вас появятся какие-то дополнительные вопросы, вы всегда сможете задать их любым удобным способом: на nag.support, на форуме, в телеграм. Характеристики всех моделей есть в даташитах, а описание команд и настройки оборудования можно найти здесь, здесь и здесь. На сайте shop.nag.ru вы также можете ознакомиться с любым ассортиментом из нашей продукции и даже задать вопрос по определенной модели, ну и, конечно, оставайтесь с нами и следите за новостями в нашем телеграм-канале SNR-SWITCH-NEWS, будет еще много интересного.
Авторизуйтесь, чтобы иметь возможность оставлять комментарии


